一、ZK基础
ZK,全称为 ZooKeeper,是一个分布式协调服务,由雅虎公司开发并开源。ZK 提供了一个高可用、高性能(Raptor测试链接同机房直连ZK节点Avg耗时0.1ms)、分布式的协调服务,用于解决分布式系统中的一些协调问题,如分布式锁、分布式协调、分布式配置中心、分布式队列等。被广泛地应用于诸如 Hadoop、HBase、Kafka 和 Dubbo 等大型开源分布式系统中,公司内部的Squirrel、MNS、Crane、Mafka、DTS以及一些业务系统也广泛使用ZK来实现数据订阅、Leader选举、分布式锁等。
1.1、ZK名词解释
LocalSession:本地会话指客户端与 ZooKeeper 服务器之间的一次连接。当客户端与 ZooKeeper 服务器建立连接时,会创建一个本地会话。本地会话的生命周期与客户端与服务器之间的连接一致。如果客户端与服务器之间的连接断开,那么本地会话也会被关闭。主要用于创建临时节点、处理读请求。
GlobalSession:全局会话是指客户端与 ZooKeeper 集群之间的一次连接。当客户端与 ZooKeeper 集群中的任意一个服务器建立连接时,会创建一个全局会话。全局会话的生命周期与客户端与集群之间的连接一致。如果客户端与集群之间的连接断开,那么全局会话也会被关闭。所有的全局会话都会同步到Leader节点,由Leader节点来统一检测其超时时间。
- TxnLog:事务日志文件,每次写请求都会转化成一个事务日志操作,一阶段提交时候会将事务日志顺序写入到事务日志文件.
- SnapLog:内存快照文件,内存Database对应的快照文件,满足一定条件就会将内存Database序列化后生成一份快找文件。
- Zxid:全局事务ID,用于标识 ZooKeeper 中的每个事务。每个 ZooKeeper 事务都有自己的 zxid,用于标识该事务的唯一性和顺序。每次新的事务请求,Zxid都会加1。
- Epoch:纪元,Epoch 用于标识 ZooKeeper 服务器的状态和版本信息,简单理解没新产生一个Leader,Epoch都会加1。
- MyId:节点ID,ZK集群中每个ZK节点的唯一标识。
- Proposal:Leader节点向所有Follower节点发送的一阶段事务提议请求。
- Commit:Leader节点向所有Follower节点发送的二阶段事务提交请求。
1.2、ZK数据结构模型
ZooKeeper 中的数据结构模型采用了类似文件系统的树形结构,每个节点都唯一关联一个路径Path,每个节点可能又会存在多个Children节点。如下图,“/mns/prod/com.sankuai.crayfish.sign”代表一个节点的Path,节点详情展示了节点的Value(data字段)以及其他属性字段值。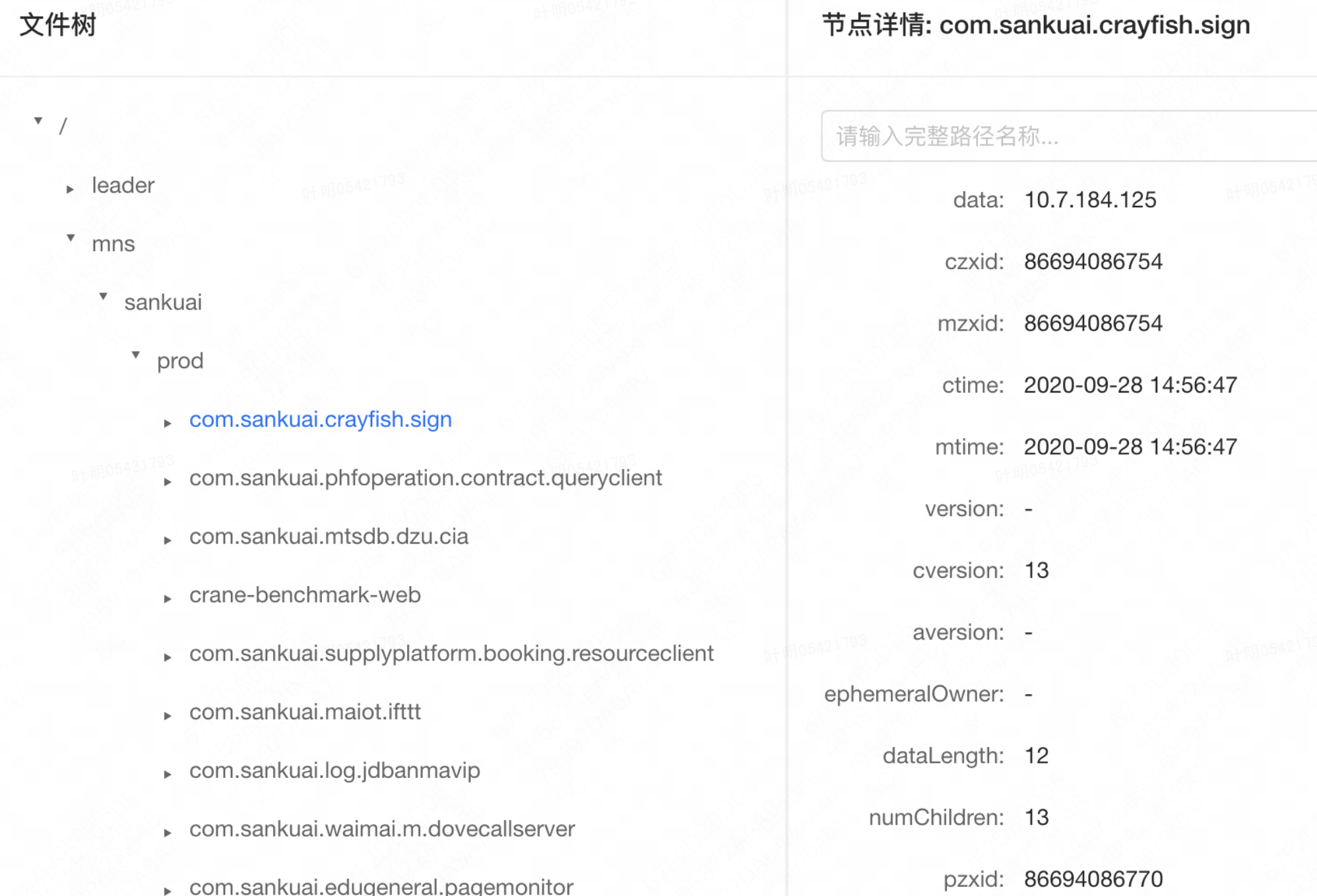
ZK会将上述树形结构包含的所有节点缓存到内存当中,生成一个内存Database,实现原理特别简单。大体上就是维护了一个 ConcurrentHashMap,其中 Key 是节点的Path,Value是节点数据 DataNode。ZK会将上述所有的节点,例如 “/”、“/leader”、“/mns”、“/mns/sankuai”、“/mns/sankuai/prod”、“/mns/sankuai/prod、com.sankuai.crayfish.sign”等等全部保存到ConcurrentHashMap中。简述下从Database中读、修改、新增数据过程
- 读数据:传入Path,从 ConcurrentHashMap 中获取DataNode,若读请求中带有watch标识,需要向该Path注册一个Watcher,后续用来监听数据变更并通知客户端。
- 修改数据:传入Path和Value,从 ConcurrentHashMap 中获取DataNode,修改 data 的值,然后修改 stat 信息,最后触发该Path上所有注册的Watcher
- 新增数据:传入Path和Value,根据传入Path解析出父节点的Path,根据parentPath从ConcurrentHashMap中获取父节点数据DataNode,父节点的children中添加传入的子节点Path。根据传入Path,创建一个新的DataNode,将其数据插入到ConcurrentHashMap中。完成上述操作后,触发该Path上所有注册的Watcher。
public class DataNode implements Record { //节点value byte[] data; //节点stat数据,上图中的czxid、mzxid、ctime等等 public StatPersisted stat; //节点children,存储子节点Path列表 private Set<String> children = null; }二、ZK架构设计
2.1、整体架构
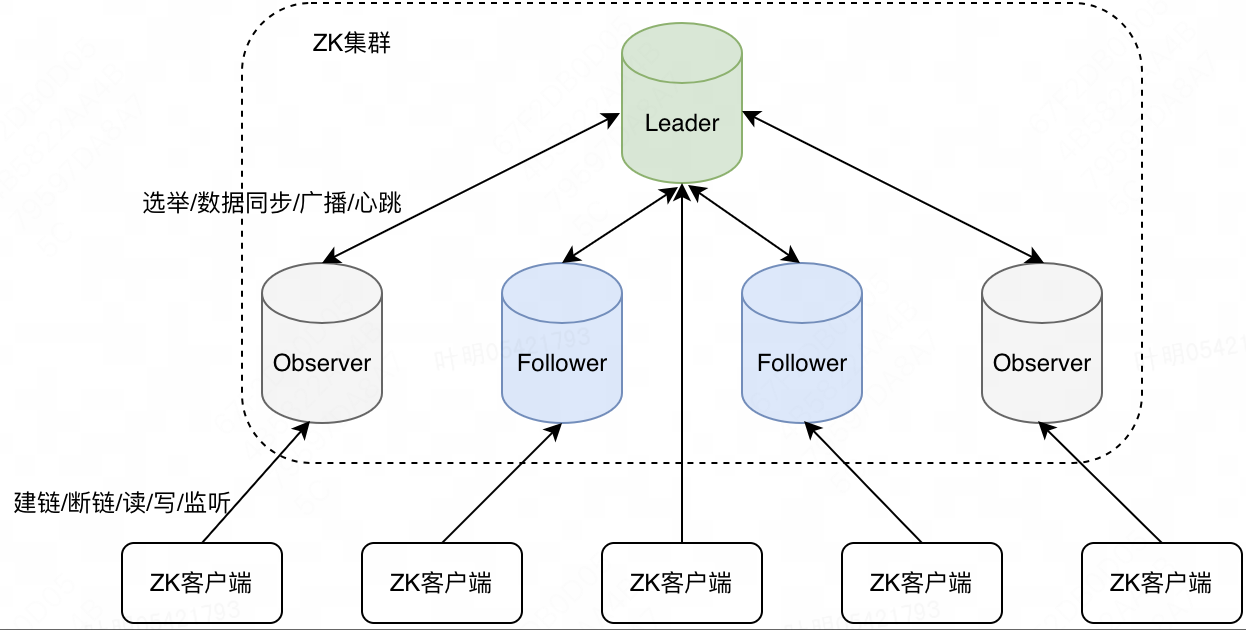 如上图所示,ZK集群服务端包括一个Leader节点、若干个Follower节点、若干个Observer节点(可选),其中 Leader 和 Follower 节点统称为Voter节点(会参与事务处理、Leader选举投票)。Leader节点会与所有Follower节点和Observer节点建立一个Socket双向通信链接,主要用作集群内部之间的通信,实现Leader选举、数据同步、数据广播和心跳检测等功能。在上述节点中,Voter节点主要有以下两个作用:
如上图所示,ZK集群服务端包括一个Leader节点、若干个Follower节点、若干个Observer节点(可选),其中 Leader 和 Follower 节点统称为Voter节点(会参与事务处理、Leader选举投票)。Leader节点会与所有Follower节点和Observer节点建立一个Socket双向通信链接,主要用作集群内部之间的通信,实现Leader选举、数据同步、数据广播和心跳检测等功能。在上述节点中,Voter节点主要有以下两个作用: - 参与Leader选举:所有voter节点会参与Leader竞选和投票
- 参与写请求二阶段处理:对于客户端的任意一个写请求,都需要半数以上的 Voter 节点ACK后,才能最终提交。
由于ZK采用类似二阶段提交协议来处理写请求,故出于性能考虑,不能配置太多的Follower节点,基于此ZK引入了Observer节点,通过水平扩容Observer节点来提升整个ZK集群处理读请求性能。
ZK客户端启动后会随机选择一个ZK节点与其建立连接,链接建立好之后,即可发起读、写、监听等各类请求。
2.2、数据广播
ZK客户端与集群中的任一ZK节点建立链接之后,即可发起读写请求。对于读请求,不管客户端当前连接的节点是Leader、Follower还是Observer,收到客户端请求之后,直接从内存Database中查到数据返回给客户端即可。对于写请求,ZK集群处理逻辑较为复杂,整体上类似一个二阶段提交的过程,详细过程参考 ZK处理客户端请求流程梳理 :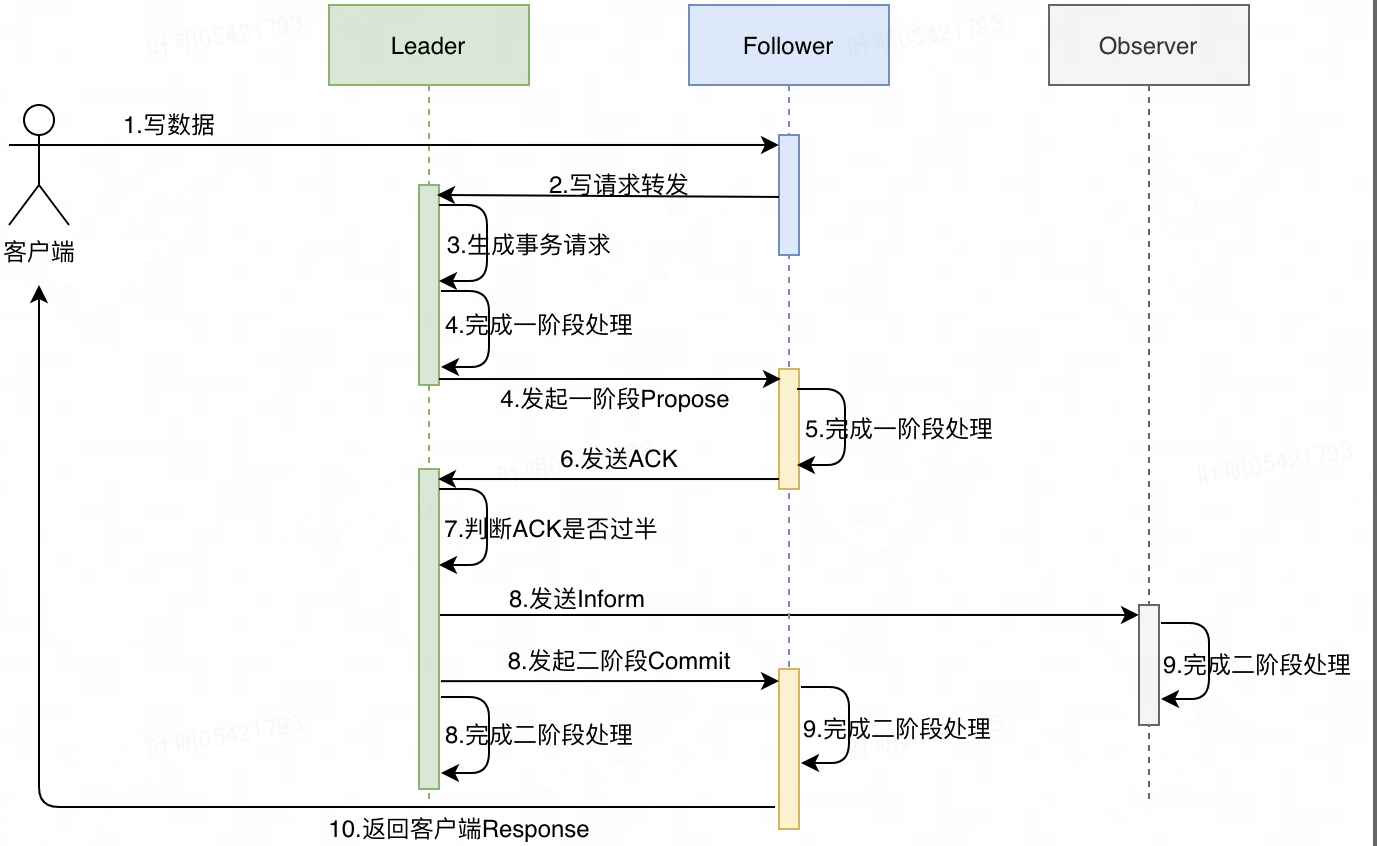
- 假设客户端与ZK集群一个Follower节点已经建立了链接,于是向该节点发送一个写请求来更新指定ZK节点的Value。
- Follower收到请求后,判断是写请求,需要向Leader发送Request请求,将写请求转发给Leader。
- Leader收到Follower的Request后,先生成一个全局事务Zxid,然后将该写请求转化成一个事务请求Proposal。
- Leader自身完成一阶段处理,并向集群中的所有Follower节点发送一阶段Propose请求,同时记录向每个Follower节点发送请求的具体时间(心跳检测会用到),然后等待Follower节点响应。
- Follower节点收到Propose后,开始一阶段处理,主要会完成两件事情:
- 事务日志落盘:将事务请求Proposal同步写入事务日志文件TxnLog,类似于MySQL WAL机制,将随机读写磁盘转换成一个顺序写磁盘的记录日志操作。
- 生成快照文件(根据条件触发):从上次生成快照文件之后,新增的事务日志条数或者事务日志占用的内存大小是否超过一定阈值,若超过阈值,开启一个子线程将当前内存中的Database数据序列化后生成一个快照文件SnapLog。
- 完成上述操作后,会在内存中记录当前处理的Zxid
- Follower节点向Leader节点发送ACK,表示一阶段已经成功执行。
- Leader节点陆续接受到Follower节点的ACK,若加上Leader节点自己处理成功的个数超过Voter节点总数的一半,则判断一阶段整体执行成功。(Leader节点要么收到从节点的ACK,要么在规定超时时间内没有收到从节点ACK请求,不存在从节点发送操作失败情况,所以不存在主动通知Follower节点回滚逻辑)
- Leader节点自身完成二阶段处理,同时向所有Follower节点发送二阶段Commit请求,向所有Observer节点发送Inform请求,此过程Leader节点不关注其他节点处理结果。
- Follower节点收到Commit请求后,会先判断Zxid是否与一阶段Pending的Zxid是否相同
- 若不同,表示由于网络丢包或者其他异常,Follower节点可能遗漏掉一些事务请求,Follower节点会直接关闭与客户端的所有链接,同时会断开和Leader的链接,直接进入“重启过程”。
- 若相同,根据事务请求的Path和Value,更新内存中Database 的数据。同时将当前已经成功Commit的事务日志缓存到内存队列committedLog(默认500条)中,并修改内存队列中的minCommittedLog 和 maxCommittedLog。
- Observer节点收到Inform请求,处理逻辑与Follower节点基本相似,不再赘述。
- Follower节点二阶段处理成功后,返回客户端操作成功(只会由最初收到客户端写请求的那个Follower节点来返回给客户端Response)。
综述,ZK基于共识协议,对于任意写请求,都交由Leader节点来协调,采用两阶段提交,第一阶段完成事务日志落盘,第二阶段完成内存Database数据更新。在不明显降低写性能的情况下,保证极端故障情况下只要Commit的数据都不会出现丢失。
2.3、心跳同步检测
Leader节点与Follower节点启动后会相互创建Socket来与对方进行通信,主要是通过相互发送Ping来实现心跳检测,心跳检测主要包含两个作用:
- 检测节点维度是否超时或者故障:以Leader为例,若发现读写Socket失败,会认为Follower异常而关闭Socket;对于Follower节点,若发现读写Socket失败,会认为Leader节点已经失效,会将自己的状态从 Following 状态变为 Looking 状态,进而发起一轮新的选举过程。
- 检测全局会话维度是否出现超时:在 ZK 集群中,客户端与ZK节点会建立一个本地Session,若客户端存在写请求,则会将该本地Session升级为全局Session,即ZK节点会将该Session信息同步到Leader节点,后续由Leader节点统一来检测所有的全局会话是否超时。
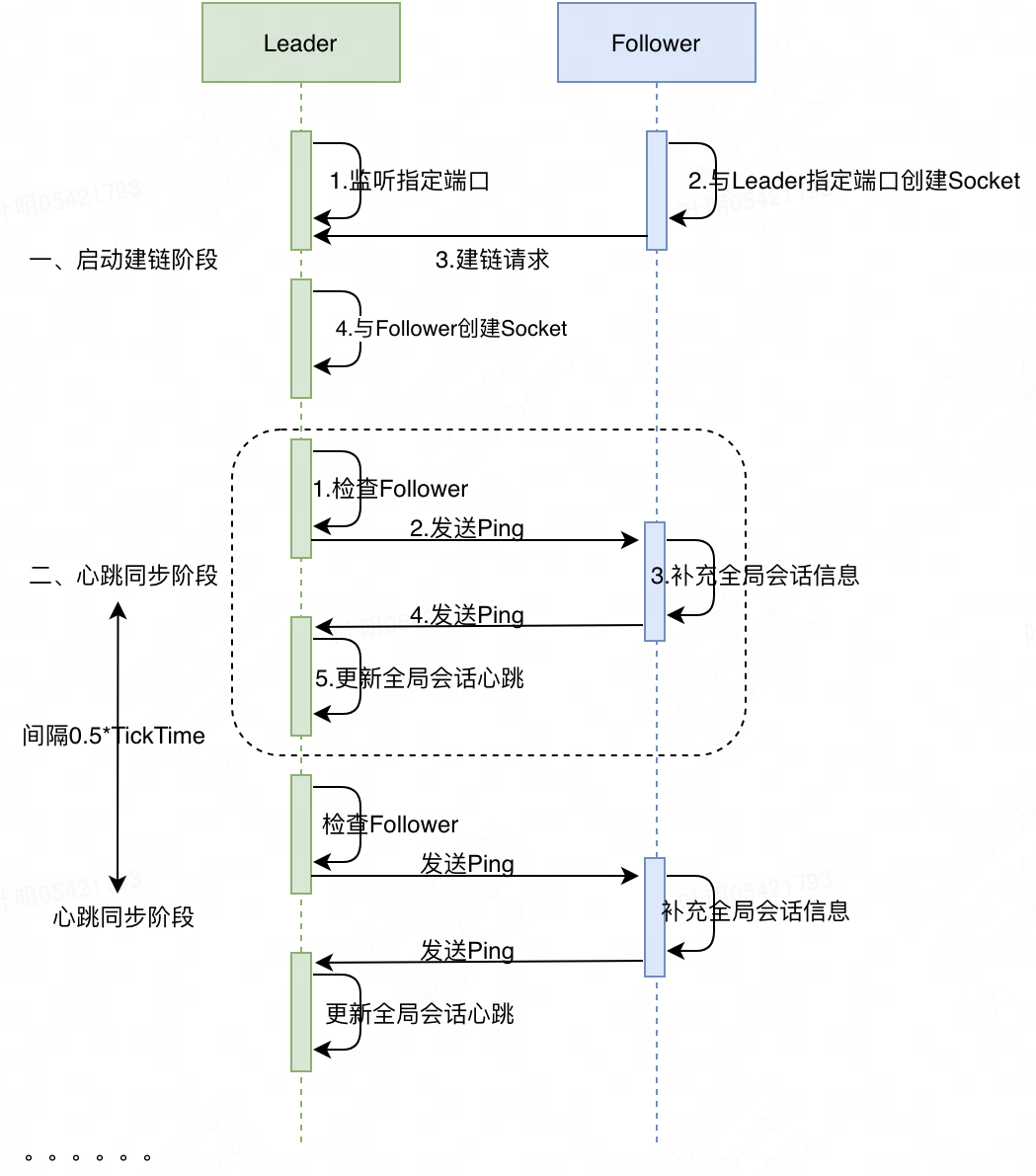
梳理下Leader和Follower节点心跳同步的过程:
- Leader每次向Follower节点发起Ping之前,会判断当前时间与上次收到Follower节点请求的时间之差是否大于超时时间,若超时,Leader节点会认为Follower节点已经失效,会主动关闭Socket链接。
- Leader向Follower节点发送Ping请求。
- Follower节点收到请求后,将本机的全局会话信息封装到 Ping 请求中。
- Follower节点向Leader节点发送Ping请求。
- Leader节点收到Ping请求,更新维护的全局会话信息(会单独启动一个线程基于该信息来检测全局会话是否超时)
间隔0.5*TickTime后,会进入到下一次心跳同步阶段,以此循环往复。
2.4、Leader选举
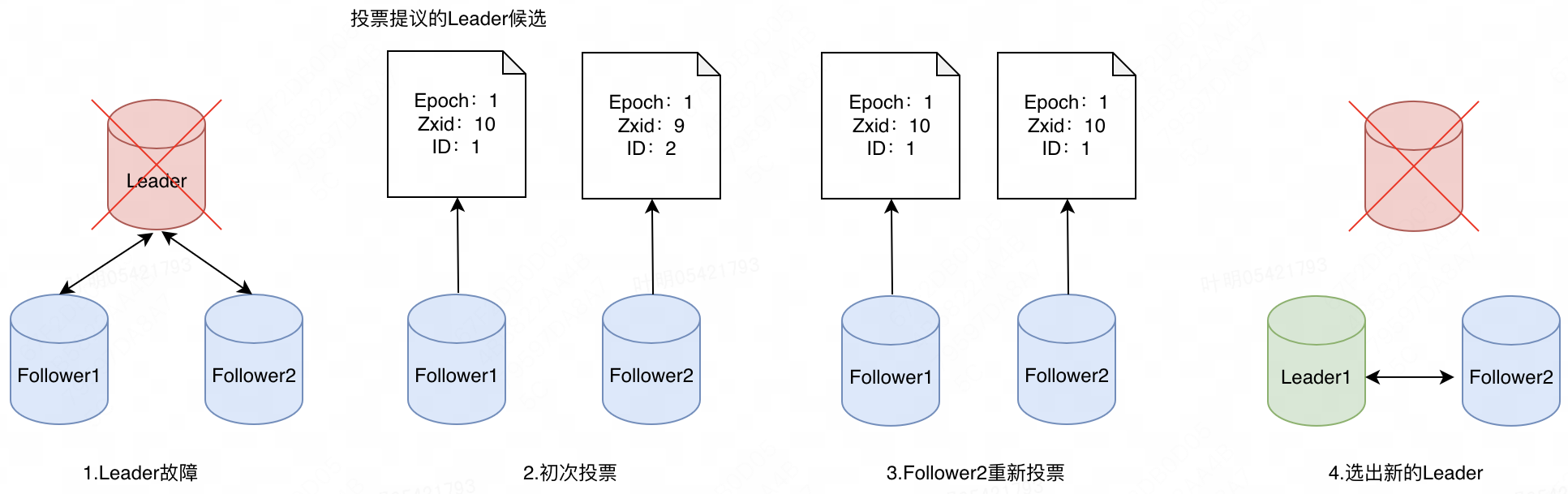
ZK节点在运行过程中存在以下几个状态:LOOKING(竞选或者寻找Leader状态)、FOLLOWING(Follower节点状态)、LEADING(Leader节点状态)、OBSERVING(Observer节点状态)。上文已经提到,当Leader正常运行时候,Follower节点会以阻塞的方式循环读取与Leader之间创建的Socket数据;一旦Leader出现故障,读取Socket会抛异常,导致循环中断,Leader会从FOLLOWING状态变更到LOOKING 状态,进而会发起一次新的Leader选举,具体选举过程如下:
- Leader出现故障,Follower1和Follower2两个节点感知到Leader故障,然后相继发起新的Leader选举。
- 初次投票,Follower节点默认都会提议自身作为Leader候选人,会将自身的Epoch、Zxid、节点ID信息同步给集群中的其他Follower。
- 先以Follower1的视角来分析第一轮选举的结果,Follower1提议自己作为Leader候选,后续又收到了Follower2提议的候选人Follower2,Follower1节点判断自身的Zxid较大,故依然维持自己的判断,但是由于获得票数只有1票,未超过集群 Voter节点的一半2个(3个Voter),故还需要等待。
- 然后以Follower2的视角来分析第一轮选举的结果,Follower2同样提议自己作为Leader候选,后续又收到了Follower1提议的候选人Follower1,Follower2节点判断Follower1节点Zxid较大,会修改自己的Leader候选人,并将最新提议的候选人广播给集群中其他节点,然后进行等待。
- Follower2重新投票后,Follower1节点收到消息后,此时Follower1节点判断自身已经得到了2票,超过集群Voter节点一半,故Follower1当选为Leader节点,然后会发出广播告知其他节点已经完成Leader选举
- Follower2节点接受到广播消息后,就会与新的Leader节点建立链接。
2.5、数据同步
此处提到的数据同步主要指节点初始化需要与Leader节点进行数据同步以保证数据一致,完成数据同步后,该节点才能对外提供服务。数据同步包含以下几种形式:
- 新节点加入集群:新的节点加入到一个ZK集群,该节点需要与Leader进行数据同步。
- 原先故障节点重新加入集群:同新节点加入集群类似,只是在数据同步之前需要先从快照文件SnapLog和事务日志文件TxnLog中恢复数据,然后同Leader进行数据同步。
- 集群选出新的Leader:集群重新选举出新的Leader后,其余所有节点都要与Leader进行数据同步。
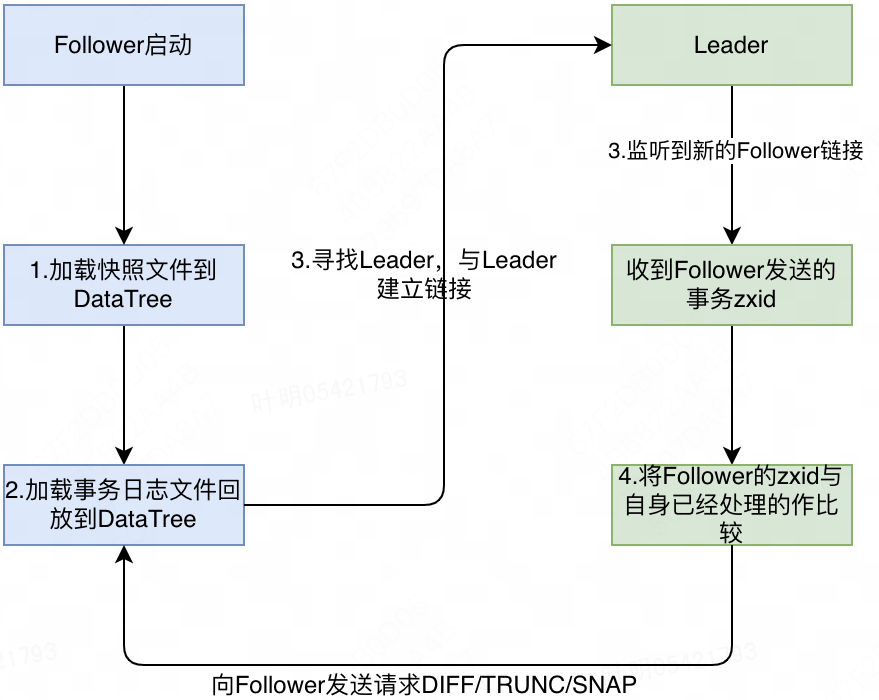
Follower启动数据同步过程如下:
- 从磁盘上加载快照文件到内存,生成内存Database,并记录当前处理的最大maxZxid。
- 从磁盘上加载事务日志文件,对于事务日志文件中Zxid大于步骤1中maxZxid的事务,都需要按照顺序加载到Database(同二阶段处理Commit请求类似直接修改Database中的数据),记录下此时最新的Zxid。
- 加载数据完成后Follower节点开始加入集群,寻找到Leader后,与其建立连接,并发送当前最新的Zxid。
- Leader接受建链请求,创建Socket,读取到Follower传过来的Zxid,将其与minCommittedLog和maxCommittedLog进行比较,比较逻辑如下:
- Zxid == maxCommittedLog,Leader 节点发送一个空的DIFF请求给Follower,Follower 收到该请求后,无需处理,直接结束数据同步过程,可以对外提供服务。
- Zxid > maxCommittedLog,说明Follower节点数据比当前Leader还新,不合理。此时,Leader节点会发送TRUNC请求给 Follower,Follower收到请求后,根据Leader传过来的maxCommittedLog,从事务日志文件中删除大于其的事务日志,然后根据快照文件和事务日志文件恢复数据。
- minCommittedLog<=Zxid<maxCommittedLog,那么Leader 节点会遍历内存队列committedLog中的事务日志,对于大于Zxid的事务日志,Leader会向Follower节点发起Commit请求,Follower节点接受到请求后,将其顺序加载到Database。
- Zxid < minCommittedLog,说明Follower节点数据太旧,Leader内存队列中已经没有缓存该事务日志,Leader节点会先从事务日志文件中找到事务ID=Zxid的日志,若事务日志文件中可以找到该Zxid的日志,且从该Zxid的日志开始到maxCommittedLog总的日志大小在制定阈值范围之内,那么Leader节点会将这些事务日志按照顺序向Follower节点发起Commit请求;若不满足上述条件,Leader节点需要向Follower节点发起一个SNAP请求,然后会将内存Database中的数据全部序列化进行发送,Follower节点接收到SNAP请求后,从Socket中读取Leader发过来的数据,将其加载到内存。加载完成后即完成了数据同步过程。
三、ZK数据一致性分析
3.1、CAP简介
ZooKeeper 是一个分布式协调服务,它的设计目标是提供高可用性和一致性的服务。从 CAP 系统定义的角度来看,ZooKeeper 更加注重一致性和分区容错性,而在可用性方面做了一定的牺牲。
- 分区容器性(Partition Tolerance):ZooKeeper 采用了主从复制的架构,将数据复制到多个节点上,以保证数据的可靠性和容错性。当主节点发生故障时,ZooKeeper 会自动切换到备用节点,保证系统的可用性和稳定性
- 一致性(Consistency):因为 ZooKeeper 主要用于实现分布式锁、配置管理、服务发现等功能,这些功能对数据的一致性要求非常高。ZooKeeper 通过使用 Paxos 算法和 ZAB 协议来保证数据的一致性和可靠性,即使在网络分区或节点故障的情况下,ZooKeeper 也能够保持数据的一致性。
- 可用性(Availability):ZooKeeper 采用了一些措施来保证系统的可用性,例如使用心跳机制来检测节点的健康状态,使用多个备用节点来保证系统的容错性,以及使用会话超时机制来避免死锁等问题。但是,为了保证数据的一致性和可靠性,ZooKeeper 在某些情况下可能会牺牲一定的可用性,例如在进行 leader 选举时,ZooKeeper 会暂停对外服务,直到选举完成。
3.2、ZK一致性讨论
根据 ZK官方 的描述,其数据一致性实际是处于强一致性和顺序一致性之间。下文简述下一致性的各个级别,严格级别从上到下层层降低。
The consistency guarantees of ZooKeeper lie between sequential consistency and linearizability. In this section,
we explain the exact consistency guarantees that ZooKeeper provides.
Write operations in ZooKeeper are linearizable. In other words, each write will appear to take effect atomically at some
point between when the client issues the request and receives the corresponding response. This means that the writes
performed by all the clients in ZooKeeper can be totally ordered in such a way that respects the real-time ordering
of these writes. However, merely stating that write operations are linearizable is meaningless unless we also talk about
read operations.
Read operations in ZooKeeper are not linearizable since they can return potentially stale data. This is because a read
in ZooKeeper is not a quorum operation and a server will respond immediately to a client that is performing a read.
ZooKeeper does this because it prioritizes performance over consistency for the read use case. However, reads in ZooKeeper
are sequentially consistent, because read operations will appear to take effect in some sequential order that furthermore
respects the order of each client's operations. A common pattern to work around this is to issue a sync before issuing a read.
This too does not strictly guarantee up-to-date data because sync is not currently a quorum operation. To illustrate,
consider a scenario where two servers simultaneously think they are the leader, something that could occur if the TCP
connection timeout is smaller than syncLimit * tickTime. Note that this is unlikely to occur in practice, but should be
kept in mind nevertheless when discussing strict theoretical guarantees. Under this scenario, it is possible that the
sync is served by the “leader” with stale data, thereby allowing the following read to be stale as well. The stronger
guarantee of linearizability is provided if an actual quorum operation (e.g., a write) is performed before a read.
Overall, the consistency guarantees of ZooKeeper are formally captured by the notion of ordered sequential consistency or OSC(U) to be exact, which lies between sequential consistency and linearizability.- 强一致性/线性一致性(linearizability):所有操作不论读写、不论是来自哪个客户端session,都是全局有序的,因为全局有序,所以需要有全局时钟,并且一定能读到最新数据。ZK写请求达到了强一致性
- 顺序一致性(Sequential consistency):每个session的请求是保证严格有序的,但是不需要全局时钟。所有的session看到数据的顺序都必须和全局操作的执行顺序一致。也就是说,虽然所有操作并不是按照严格时序执行的,但是所有session读取时看到的顺序都是唯一确定的。你也可以这么理解:线性一致性会把所有请求按请求时间戳排队,任何时刻读取都能读取到最新的数据。而顺序一致性保证任何时刻读取的数据顺序都是一致的即可,也就是不要求一定读到最新数据。ZK读请求实现了顺序一致性
- 因果一致性(Causal consistency):每个session的请求是保证严格有序的,其他session读到的数据不一定是按全局顺序的,但是一个session发出的请求顺序一定是确定的。比如某个session更新a=2后再更新a=1,其他session可以拿不到a=1这个最新值,但是不能拿到a=1之后又拿到a=2,因为这和更新者发起的顺序不相符。但是如果a=2和a=1是不同session发出的,那对于其他session来说,谁先谁后就无任何要求
顺序一致性和因果一致性的区别就在于:系统是否需要对多个来源的数据重新排队,需要重排队的就是顺序一致。不需要重排队,保证每个数据来源顺序一致就可以的话,是因果一致。 - 最终一致性(Eventual consistency):最终一致性只是定义了系统停止新的写入后,在一段时间内,任何session读取的数据都将一致。此外什么也不保证,“一段时间”是多久也没说,属于最弱的一致性。
ZK Leader节点和Follower节点基于TCP链接的FIFO特性来保证节点接受到的读写请求一定能按照顺序被节点执行。对于写请求来说,由于都会经由Follower节点转发到Leader节点统一处理,Leader节点根据接受到的请求顺序来执行两阶段提交过程。由于在二阶段Commit阶段,节点对于写请求的处理是单线程串行执行,所以对于写请求,不会出现旧数据覆盖新数据的情况。
对于读请求,出于性能考虑,集群中任一ZK节点都能直接响应客户端的读请求,直接从内存Database查询到数据后即可返回给客户端,故读请求有可能读到旧的数据,同数据库、Redis其他存储组件读取从库也有概率读取到旧数据类似。当然ZK也提供了解决方案,在每次读请求之前,客户端可以先发起一个Sync请求,收到Sync请求后的ZK节点会从Leader节点同步最新数据,显然该操作会降读请求的性能,同时给Leader带来较大压力,一般不建议使用。
四、ZK中潜在优化点
4.1、事务日志同步落盘影响写入性能
我们知道ZK一般更适合于读多写少的业务,根据线下环境对一个类似MNS的集群进行压测,该集群能支撑最高1000QPS的写入请求(ZK集群机器配置、以及写入数据大小不一导致性能可能会有差异)。上次机房故障,MNS集群和外卖公用集群由于整体写入明显增加导致集群近乎不可用。
性能瓶颈原因:通过上文对ZK写入过程的剖析以及测试,我们不难发现影响整体写入的瓶颈主要是在一阶段,Leader节点和Follower节点对于每条事务日志请求都需要同步落盘。根据测试结果,每条事务日志落盘大致耗时10ms(取决于写入大小),两阶段提交网络通信耗时2ms,其他过程耗时几乎可以忽略。
public synchronized void commit() throws IOException {
Transaction transaction = Cat.newTransaction("ZK", "commitTxnLog");
try{
if (logStream != null) {
logStream.flush();
}
for (FileOutputStream log : streamsToFlush) {
log.flush();
//forceSync默认为true,每次写请求都需要将事务日志刷盘
if (forceSync) {
long startSyncNS = System.nanoTime();
FileChannel channel = log.getChannel();
channel.force(false);
syncElapsedMS = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startSyncNS);
if (syncElapsedMS > fsyncWarningThresholdMS) {
if (serverStats != null) {
serverStats.incrementFsyncThresholdExceedCount();
}
LOG.warn(
"fsync-ing the write ahead log in {} took {}ms which will adversely effect operation latency."
+ "File size is {} bytes. See the ZooKeeper troubleshooting guide",
Thread.currentThread().getName(),
syncElapsedMS,
channel.size());
}
ServerMetrics.getMetrics().FSYNC_TIME.add(syncElapsedMS);
}
}
while (streamsToFlush.size() > 1) {
streamsToFlush.poll().close();
}
// Roll the log file if we exceed the size limit
if (txnLogSizeLimit > 0) {
long logSize = getCurrentLogSize();
if (logSize > txnLogSizeLimit) {
LOG.debug("Log size limit reached: {}", logSize);
rollLog();
}
}
}catch (Exception e){
transaction.setStatus(e);
}finally {
transaction.complete();
}
}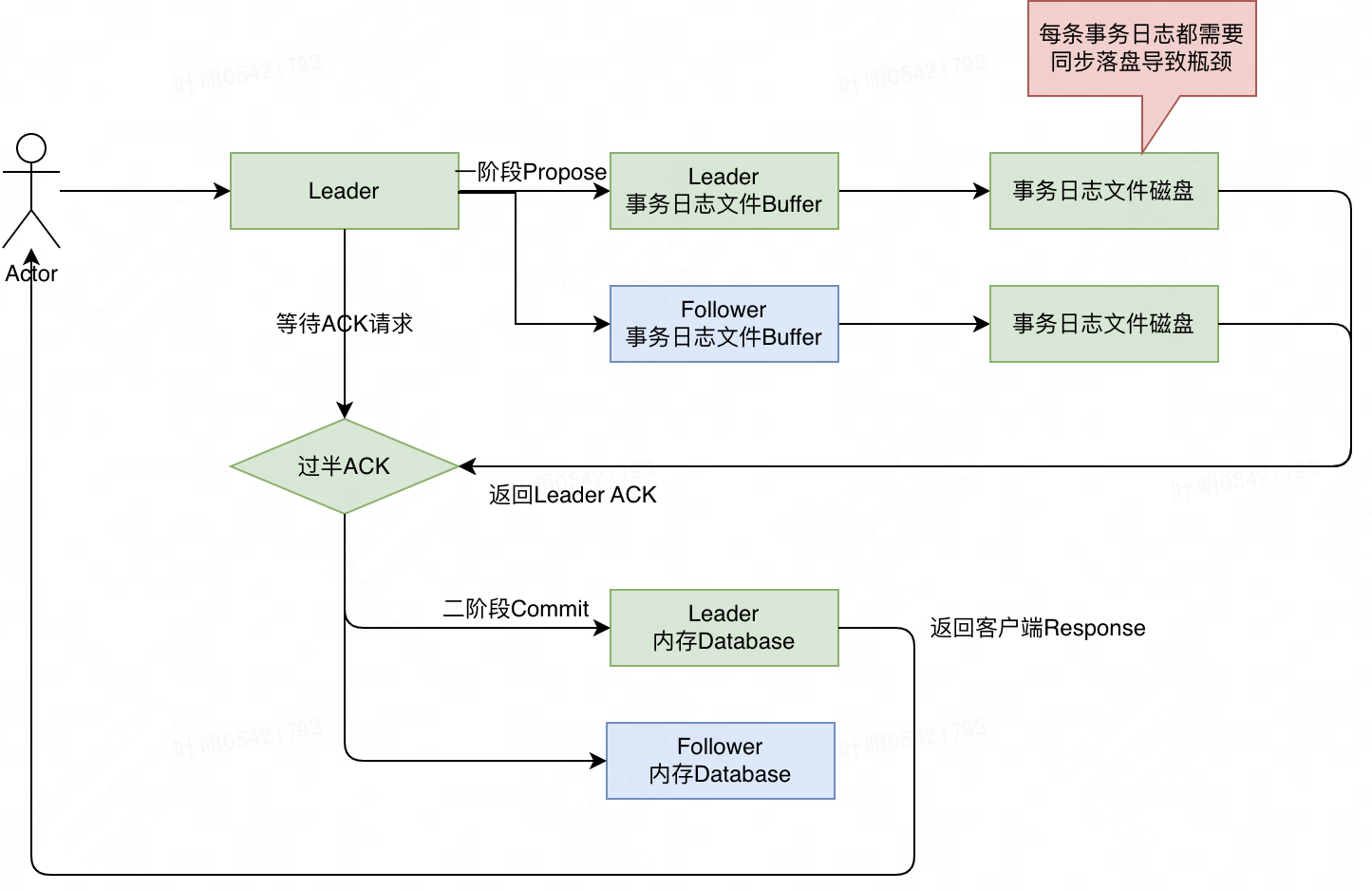
优化方案:一阶段提交,每次只需要将事务日志写入到文件Buffer,即返回给Leader节点ACK。单独启动一个线程来异步的Buffer中的数据输入到磁盘,刷入策略支持每收集到N条事务日志或者每间隔N秒将一批事务日志写入到磁盘。以上策略类似MySQL sync_binlog配置,sync_binlog支持0、1、N三种不同配置
- 0:binlog sync磁盘由操作系统负责,性能最好,有较大概率丢失数据。
- 1:每次事务请求都需要将Binlog刷盘,适合于对数据一致性有严格要求。
- N:每收到N次事务请求将Binlog批量刷盘,兼顾性能和数据一致性。
ZK的事务日志写入当前支持类似0和1两种配置,尚不支持N配置。
改造收益评估:采用优化方案,相同机器配置集群支撑最大写入QPS预计从1000至少提升到5000,端到端平均耗时也从10ms降低到2ms,集群整体稳定性会有明显提升。
改造风险评估:极端情况下,Leader和Follower节点同时故障情况下,集群最多会丢失N条数据。当前现在线上集群一般是1个Leader2个Follower配置,Leader和其中一个Follower节点同时故障出现的情况概率极低。假设真的出现,相较于集群整体会不可用,丢失几条数据带来的影响几乎可以忽略。
4.2、Leader节点压力较大
ZK Leader节点对于集群整体可用性尤其关键,一旦Leader节点出现故障,集群会重新选举Leader,在重新选出Leader节点之前的这段时间,集群都处于不可用的状态。而在以下方面,由于现在架构的设计,导致Leader节点承担了较大的压力。
- ZK Leader节点接收到过半数Voter节点的ACK后,需要通知所有Follower节点进行二阶段Commit,同时还需要通知所有的Observer节点。现在线上多数集群都是1个Leader、2个Follower,但是Observer节点数特别多,以MNS集群为例,有100多个Observer节点,相当于每次写请求,Leader节点通知次数都需要放大100多倍。
解决方案:升级到3.6版本,开启ObserverMaster模式,开启该模式后,Follower会作为Observer的代理Leader,后续Leader不再负责二阶段Observer数据的同步,由余下的Follower节点来均衡的负责Observer节点数据的同步,显著降低了Leader的压力(Leader节点网卡出入流量成比例下降,由于压测QPS不高、Observer节点个数不多,cpu降低不明显)。 - 全局会话GlobalSession超时会由Leader广播给所有ZK节点,一旦Leader处理大量连接超时、断开时,会将断链请求传导到全集群,导致全集群节点因处理“断链请求”繁忙,不能响应客户端keepalive请求,诱发客户端超时重连。之前线上MNS集群出现过类似情况,值得注意的是,由于之前线上Sgagent会直连ZK集群,导致全局会话过多,加大了上述现象出现的概率。(当前MNS集群出现该Case概率明显降低)
解决方案:修改代码,Leader发现GlobalSession超时,只需要向该Session关联的节点发起断链请求,无需向其他节点发起断链请求。
4.3、不太合理的重启机制
ZK现有设计中,较多异常场景下都会触发各种重启操作,例如以下场景:
- 客户端写入或者读取数据超过1MB,服务端会直接断开客户端链接(并不能从根本上解决问题,断开链接后,客户端重连依然会读取或者写入大数据)
- 代码很多地方抛了一个异常,就会触发系统退出
- Follower节点Commit阶段与Propose阶段Zxid不一致,Follower节点直接退出JVM进程
目前线上没有统计出异常情况导致进程退出的具体数目,同线上其他Java服务类似,当前ZK进程被supervisord托管,即使出现进程退出,也会很快被重新拉起来,所以这个问题暂时没有造成太大影响。个人猜测,ZK直接退出进程可能是由于当前架构较为复杂,客户端、主从之间需要频繁进行通信来保持集群数据一致,对于一些特殊的异常,没有思考清楚应该如何优雅处理。只能依赖进程退出,节点重启后加入集群会经过数据同步而恢复到可用状态。
优化方案:可以针对这类情况,先添加Raptor打点,后面出现问题再分析具体报错日志,针对性解决问题,尽可能缩小影响范围。(例如对于场景3,可以采用上文提到的数据同步来恢复不一致数据,从而无需机器重启)
4.4、3.4版本ZK集群每次初始化都需要重新加载快照文件
ZK 3.4.X版本在以下场景下:1节点宕机重启、2集群产生了新的Leader节点需要连接到新Leader、3节点与Leader由于网络故障恢复后重连等场景下节点都需要重新加载磁盘上的快照文件,加载快照文件会消耗大量的磁盘IO和CPU资源,同时整个过程耗时较长。实际上除了场景1,场景2和场景3由于节点内存Database数据还在,理论上并不需要重新加载快照文件。在3.6.X版本,ZK已经进行了优化,仅仅只有宕机重启才需要加载快照文件,其他场景已经无需加载快照文件。
后续优化方案:尽快推动3.4.X版本集群尽快升级到3.6.X。
4.5、Zxid超过2亿会溢出
Zxid包含8个字节,共64位,高32位用来表示Epoch,低32位表示事务序列号,如果没有产生过新的Leader,则Zxid最多只能2^32(2亿多) 个事务;若产生了一个新的Leader,则高32位自增加1,低32位重新置为0。线上DTS集群由于写入较多(不太合理),每间隔一段时间就可能会出现 Zxid溢出情况
4.6、不支持客户端批量读取功能
当前ZK服务端和C语言客户端暂不支持一些常用API的批量读取功能,诸如MNS一些重度依赖ZK的组件在服务启动阶段往往需要读取大量配置,导致启动过程耗时较长。目前我们已经对ZK服务端源码和C语言客户端源码做了二次开发来支持批量读取功能,目前本地测试功能OK,预计下个Q会开始在线下环境进行测试。

