一、简介
ZK整体构成包括Leader、Follower、Observer以及客户端,其中Leader、Follower参与Leader竞选,并负责对于写请求进行投票。由于每次写请求,Leader都必须和所有Follower基于类似两阶段提交协议来决定写入是否成功,所以Follower节点不能过多。同时为了提高集群整体的读性能,进而引入了Observer节点。下图描述了从客户端发起一次请求到服务端响应的整个过程(假设客户端此时连接的是Follower节点,相比于连接Leader处理过程更为复杂)
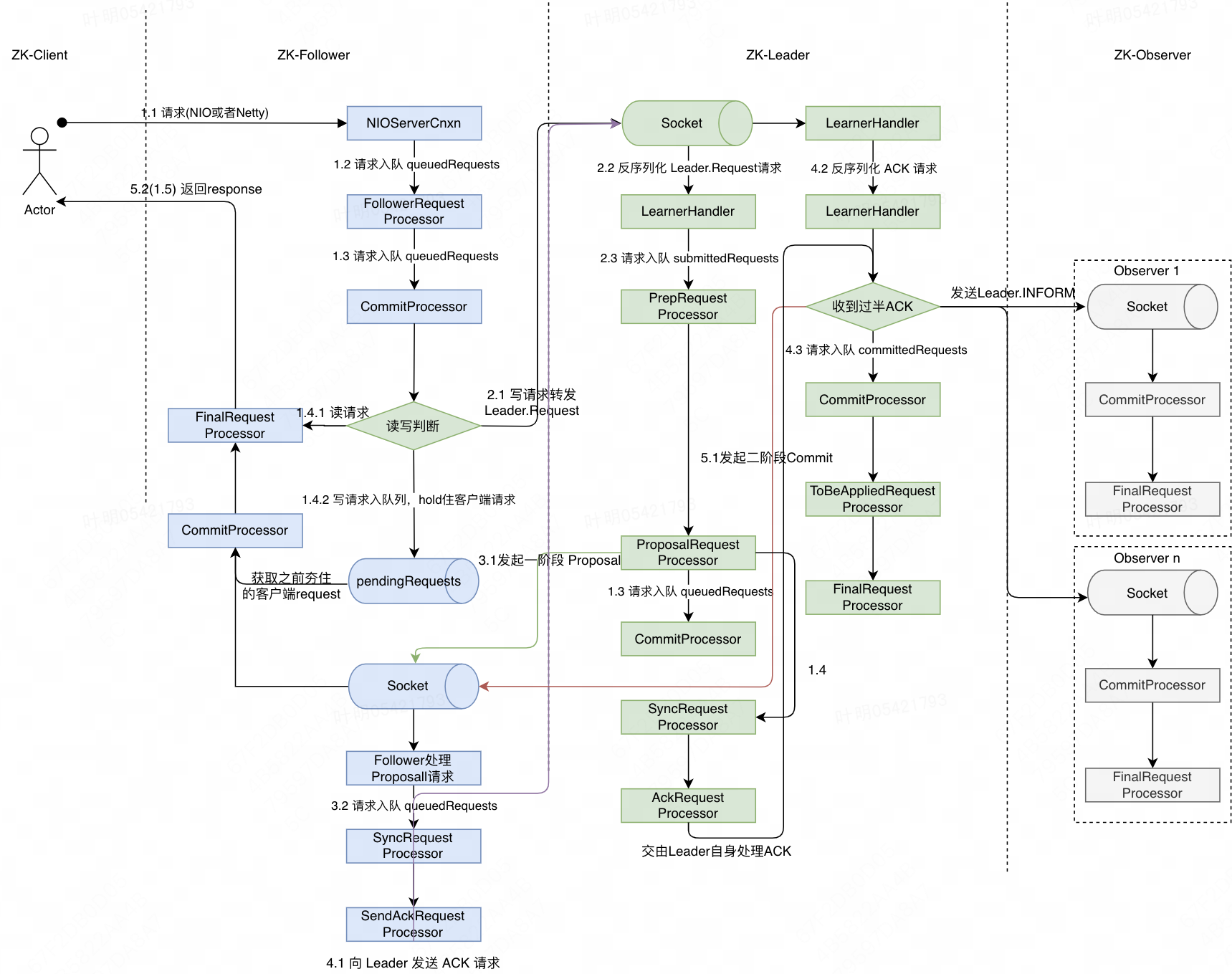
二、读请求处理过程
- 客户端向直连的ZK发起一次请求
- ZK 服务端启动时候会创建 NIOServerCnxn(3.6版本支持Netty,可以采用NettyServerCnxn),来监听客户端读写请求。收到客户端请求后,经过一系列处理,最终交由 FollowerRequestProcessor 进行处理。(ZK中会有一系列 RequestProcessor,基于Java责任链模式,每个 RequestProcessor 会同时持有下一个待执行的 RequestProcessor。一般每个 RequestProcessor 会缓存一个待处理的请求队列,类似生产者消费者模型:若下一个 RequestProcessor 是耗时操作,当前 RequestProcessor 会把请求提交到下一个 Rrocessor 的队列当中,下一个 RequestProcessor 会有一个线程来轮询处理队列中的请求;若下一个操作是非耗时操作,会直接提交下一个RequestProcessor 进行处理 )
- FollowerRequestProcessor 将请求传递给 CommitProcessor,CommitProcessor 判断若是读请求,会直接交由一个线程池调用下一个 FinalRequestProcessor 进行处理。
- FinalRequestProcessor 直接查询本地zkDb中的数据,然后返回给客户端。
三、写请求处理过程
- (Follower处理)若 CommitProcessor 判断是写请求,会将客户端 request 缓存到叫 pendingRequests的队列,同时将写请求转发给 Leader 节点(Leader 节点会通过 Socket 与所有Follower和Observer建立一个双向通信链接,此时 Follower 会向Leader发送一个 Leader.Request Packet。)
- (Leader处理)Leader 节点收到请求Packet后,经过反序列化,最终由 LearnerHandler 将请求传递给 PrepRequestProcessor。对于写请求,会将其转换成对数据存储的操作,并最终由后续Processor进行处理
- (Leader处理)PrepRequestProcessor 将请求传递给 ProposalRequestProcessor ,Proposal 会向所有 Follower 发起第一阶段提交协议,即 Proposal 请求,然后调用下一个Processor CommitProcessor进行处理。同时自身也会调用 SyncRequestProcessor ,最终经由 AckRequestProcessor 调用 Leader.processAck 方法,该方法会判断是否有过半节点 ACK(包括leader自身),由于此时只有 Leader 处理成功,暂时不能提交。
- (Follower处理)Follower 节点收到 Leader 的Proposal 请求后,交由 SyncRequestProcessor 进行处理,SyncRequestProcessor 提交事务操作和写入快照snapshot后,将请求转发给 SendAckRequestProcessor,SendAckRequestProcessor 会向 Leader 发送 ACK Packet。
- (Leader处理)Leader 收到 ACK Packet 后,经过反序列化,最终调用 Leader.processAck 方法进行判断,同上述步骤3中判断,若过半节点 ACK 成功,则会向所有Follower发送二阶段提交请求 Commit,同时向所有 Observer 发送 Inform 请求(方便 Observer 及时更新最新数据)。然后将请求添加到 CommitProcessor 的 commitedRequests队列中,CommitProcessor 最终将请求传递给 FinalRequestProcessor,在 FinalRequestProcessor 中,会完成对 ZKDB数据的更新操作。
- (Follower处理)Follower 节点收到 Leader 的 Commit 请求后,经过反序列化后交由 CommitProcessor 进行处理。以上图中的 Follower 1为例,从 pendingRequests 中获取到最初客户端缓存的请求,然后交由 FinalRequestProcessor 进行处理,FinalRequestProcessor 完成 ZKDB 数据更新之后,即可将 response 返回给客户端。对于其他 Follower 节点,只需更新 ZKDB数据即可。
- (Observer处理)Observer 收到 Inform Packet 后,待补充
四、可优化点
- 当前除正常的写请求以外,所有的创建连接、关闭连接(全局链接,只要有写操作就是全局链接)请求也会转给给 Leader ,然后 Leader 进行两阶段提交。极端情况,若Leader检测到大量链接超时,会向所有 Follower 和 Observer 发起两阶段请求关闭链接(之前出过 case,一个重要原因还是之前 sgagent会直连 zk,导致 leader 节点全局链接过多),导致集群中多个节点不可用。
改进点:创建连接和关闭连接应该不需要同步给集群中所有节点,只需要同步给指定节点。 - 对于所有的写请求,在二阶段提交的时候,都需要由 Leader 将请求同步给所有的 Observer,以 MNS ZK 集群为例,当前有 100多个 Observer,每次写请求 Leader 都需要转发 100多次请求。
改进点:为了降低 Leader 压力,可以将 Inform 操作交由 Follower 节点。

