一、背景
最近一段时间,一到业务午高峰,外卖集群的一些订阅机器就会出现Binlog消费大量延时。出现Binlog延时的原因主要是:一般11点开始,外卖业务进入中午午高峰,数据库的Binlog QPS会逐渐增加,一旦订阅服务出现性能瓶颈,处理Binlog的能力跟不上Binlog生成的速度,就会导致消费Binlog出现延时,并且延时时间会越来越长。业务在BCP上配置的核对规则一般最小是60s,一旦Binlog延时时间超过60s,那么规则就会大量误告。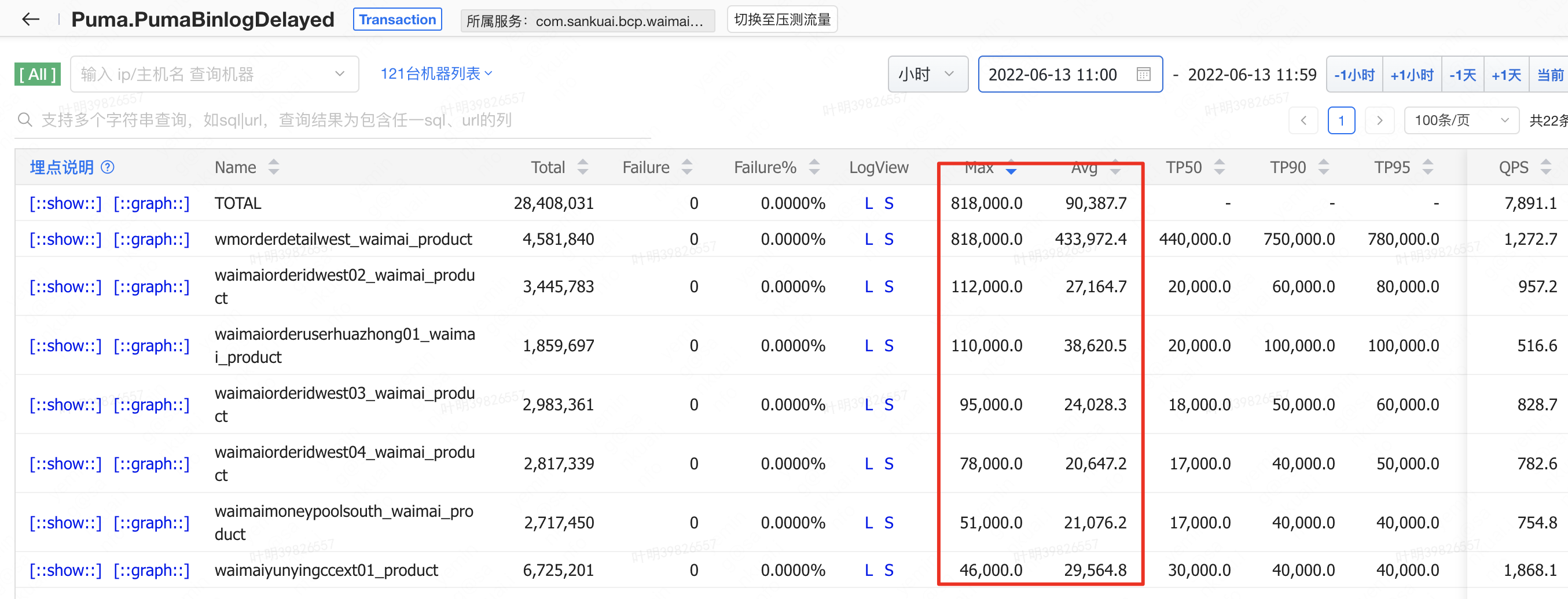
二、Binlog消费线程分析
排查性能瓶颈之前,需要先梳理出当前订阅服务消费Binlog的整体流程,如下图,整体流程大致包含7个步骤
| 步骤 | 过程描述 | 影响性能因素 | Binlog延时原因分析 |
|---|---|---|---|
| 1 | 启动一个独立线程,实现了MySQL同步协议,伪装成Slave,从业务DB实时拉取Binlog字节流,并将其解析成常规的Binlog结构 | 外部原因:网络原因导致的MySQL主从同步延时;内部原因:Binlog解析出现性能瓶颈 | Raptor监控看,当前无主从同步延时;另外根据以往测试,目前单库Binlog极限解析速度能达到20000QPS(外卖午高峰单库QPS最多5000+) |
| 2 | 解析出来的Binlog写入到内存中的LinkedBlockingQueue(历史架构图原因,之前Binlog解析和拉取是两个独立服务,通过Netty交互,后来合并成一个服务) | 步骤3拉取Binlog过慢,导致步骤2写入Binlog出现阻塞 | 根据1的分析,理论上2的写入速度能达到20000QPS,故该步骤无性能瓶颈 |
| 3 | Binlog拉取线程从LinkedBlockingQueue中拉取Binlog | 步骤2写入Binlog过慢,导致步骤3拉取Binlog出现阻塞 | 单纯从LinkedBlockingQueue中拉取Binlog,显然无性能瓶颈 |
| 4 | 将拉取到的Binlog基于业务主键进行hashCode交由不同的BlockingQueue,提高性能的同时保证Binlog处理局部有序性 | 步骤5拉取Binlog过慢,导致步骤4写入Binlog出现阻塞 | 该步骤仅根据Binlog计算hashCode,耗时基本可以忽略,无性能瓶颈 |
| 5 | Binlog聚合线程从LinkedBlockingQueue中拉取Binlog,对每条Binlog执行业务配置的Aviator filter脚本和Java匹配脚本,对满足提交的Binlog进行压缩序列化 | 同一条Binlog上关联的业务规则较多,需要执行较多业务配置的filter脚本和Java核对脚本 | 存在性能瓶颈 |
| 6 | 将聚合好的Binlog交由Binlog存储线程池进行处理 | 存储线程池处理性能 | 线程池没有抛出拒绝策略,且阻塞队列也没有积压,无性能瓶颈 |
| 7 | 将Binlog写入到Squirrel | Squirrel性能 | Raptor监控看,Squirrel各项指标正常,耗时没有明显增加,写入没有报错,无性能瓶颈 |
总结:整体上看,订阅服务Binlog消费过程是一个典型的生产消费者模型:
- 生产者:步骤1、2
- 消费者:步骤3、4、5、6、7
当前生产者理论上能达到20000QPS,外卖午高峰单库QPS 5000+,故生产者当前无性能瓶颈;消费者3、4、5、6、7中,3、4、5基本是同步处理,其中一个步骤处理慢就会影响整个过程。6和7是异步处理的,和3、4、5基本独立,不会影响3、4、5的性能。故整体性能瓶颈在3、4、5,其中3和4都是很轻量级的操作,耗时基本忽略不计,所以性能瓶颈大概率是步骤5
三、Binlog聚合线程分析
private void processMultiBinlog(BlockingQueue<EventEntry> changedEvents, int threadNo) {
while (!Thread.currentThread().isInterrupted()) {
EventEntry eventEntry = rowChangedEvents.poll(10, TimeUnit.MILLISECONDS);
Transaction t1 = Cat.newTransaction("processBinlogMsg", rowChangedEvent.getJdbcRef());
try {
for (SubMsgConfigDTO config : configMap.values()) {
Transaction t2 = Cat.newTransaction("createCacheValue", config.getId().toString());
try {
filterConfig = createCacheValue(rawData, config, sb, config.getSaveToList());
} finally {
t2.complete();
}
}
}finally {
t1.complete();
}
}
} 内层 Transaction 耗时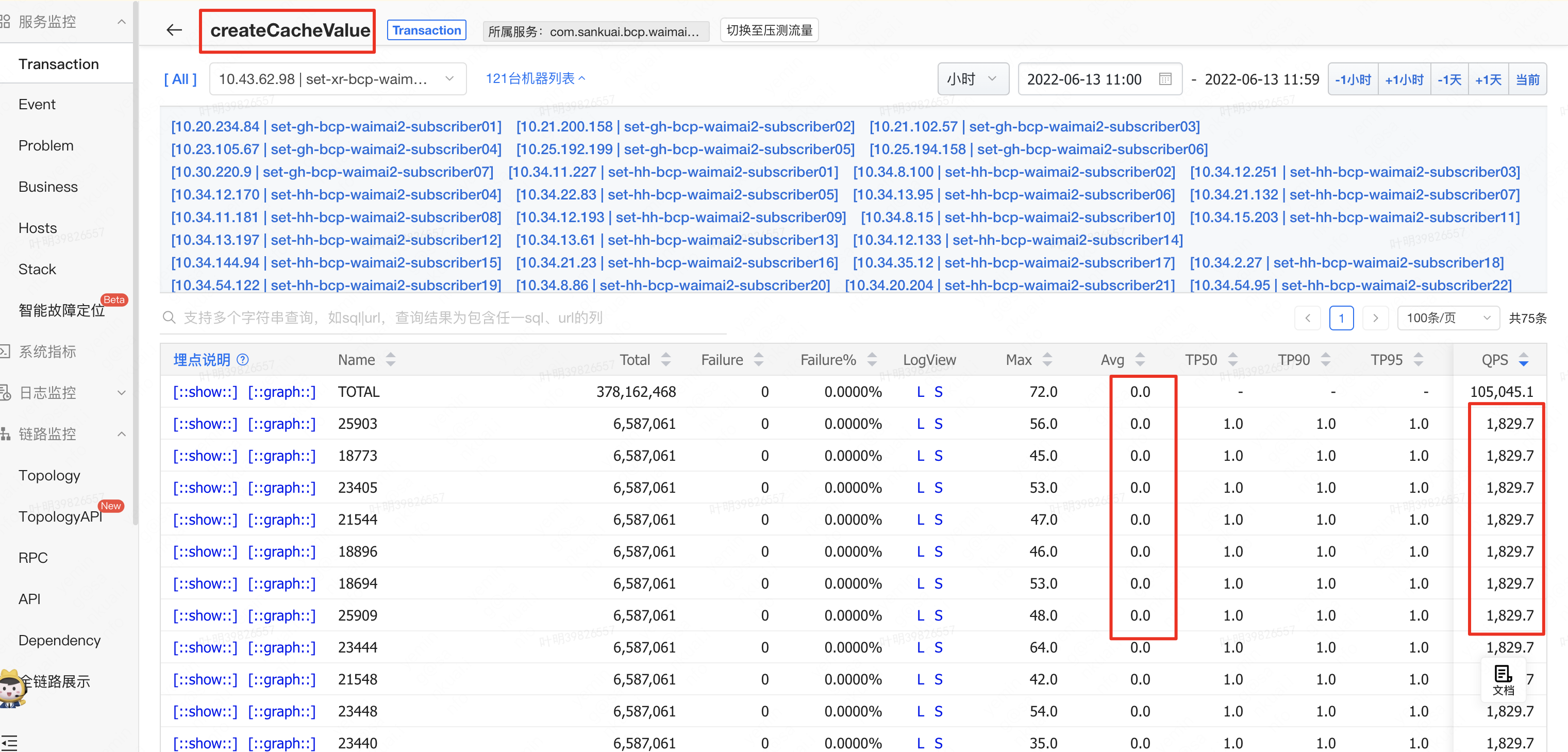
外层 Transaction 耗时
看Raptor监控,内层Transaction:createCacheValue平均耗时0ms,而外层Transaction:processBinlogMsg 平均耗时1.1ms(理论上最高qps 1000)。数据上看比较奇怪,即使内层循环执行70次,外层平均耗时应该也还是0,只能怀疑单个内层循环执行时间太短,导致被统计成0ms了。故优化思路:将串行执行createCacheValue修改成并行执行。
并行化优化后,平均处理时间从1.1变成0了。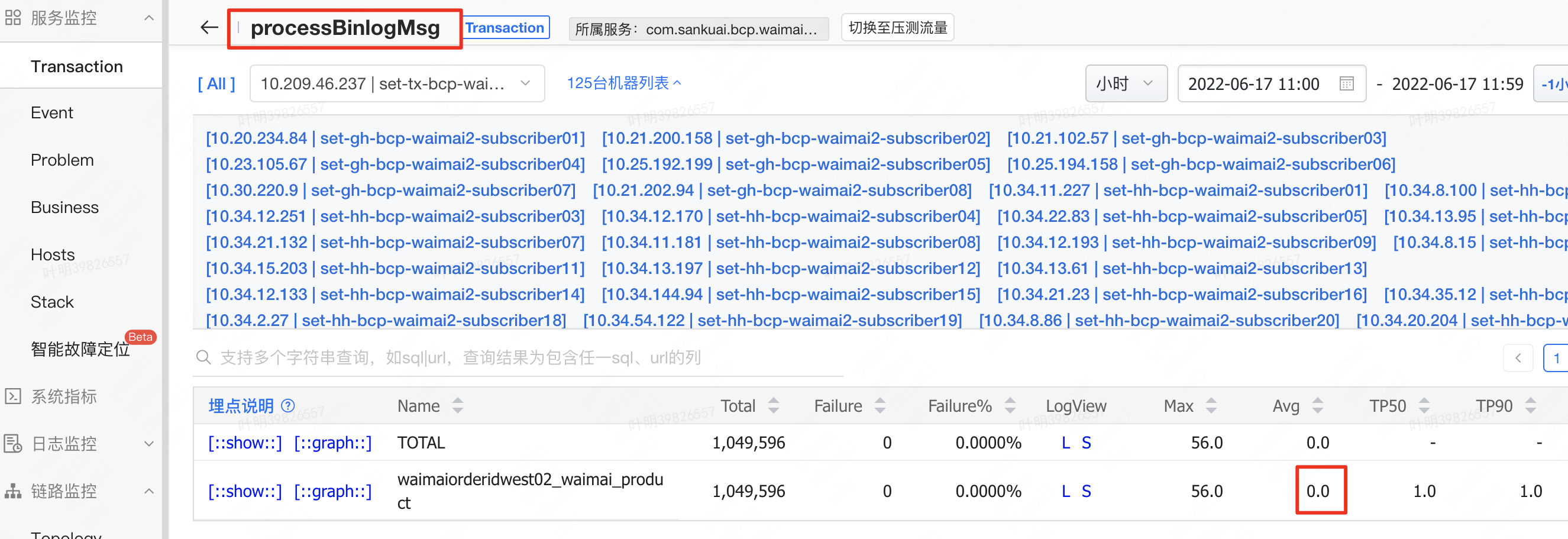
四、确定最终优化方案
优化方案与初始方案不同在于:初始方案使用了4个线程分别拉取4个不同的阻塞队列,优化方案使用4个线程拉取同一个阻塞队列。粗看上去,两个方案似乎没有区别。仔细分析下初始方案,由于生产方步骤4产生Binlog较快,故很自然的就想到了使用4个不同的阻塞队列,交由4个不同的线程去处理。但是考虑下面一种情形,若BlockingQueue1满容,此时聚合线程1的上一个任务还没有结束,步骤4又产生了一条Binlog,将Binlog写入BlockingQueue1就会阻塞,进而就阻塞了整个处理流程。反过来看优化方案,若BlockingQueue1满容,即使聚合线程1的上一个任务还没有结束,聚合线程2、3、4只要任务结束,就会从队列中拉取Binlog,后续步骤4产生一条新的Binlog写入队列也不会阻塞。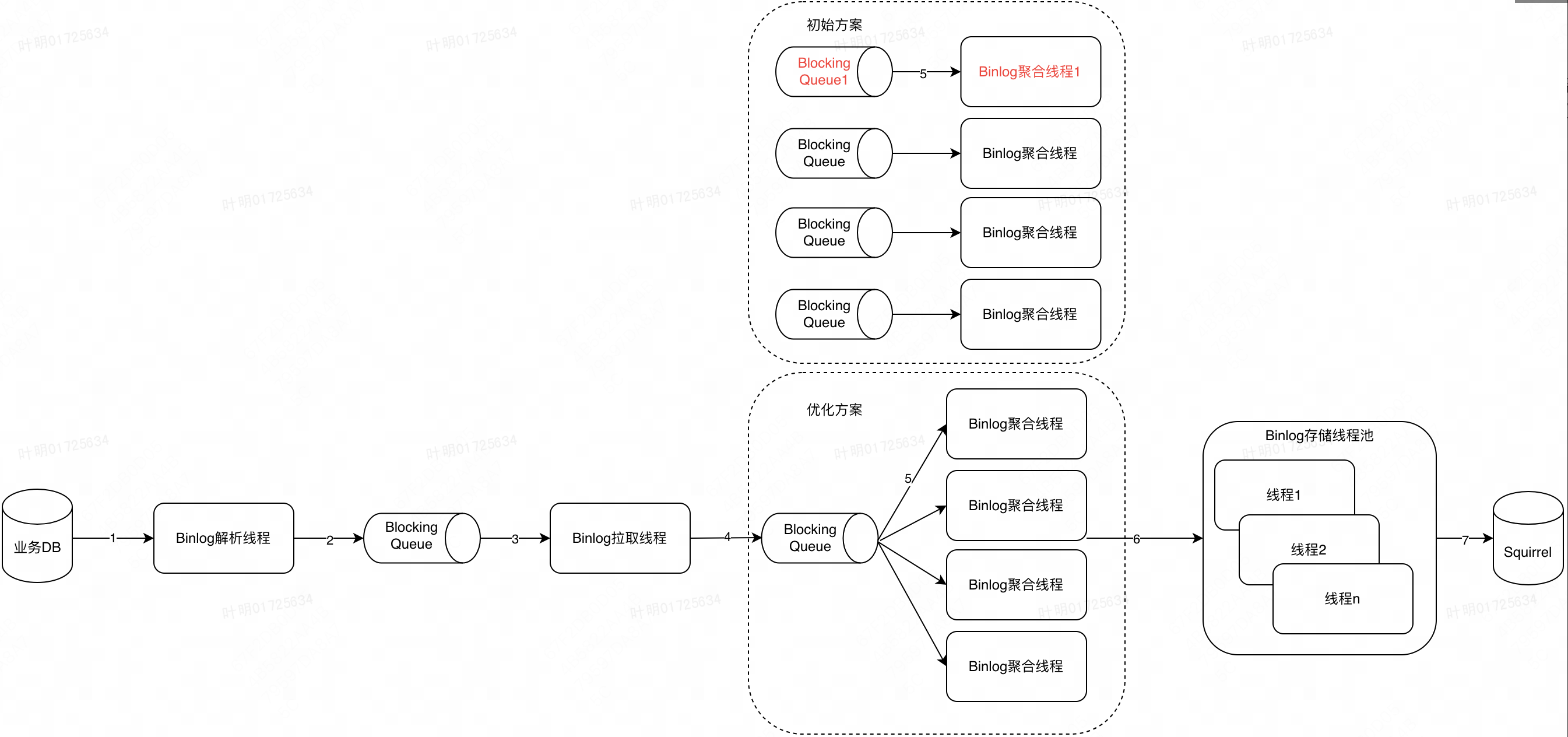
线上开启5个Binlog聚合线程进行测试,外卖订单waimaiorderidwest02_waimai_product单库Binlog消费速度达到320K/min(当前外卖午高峰一般150K/min)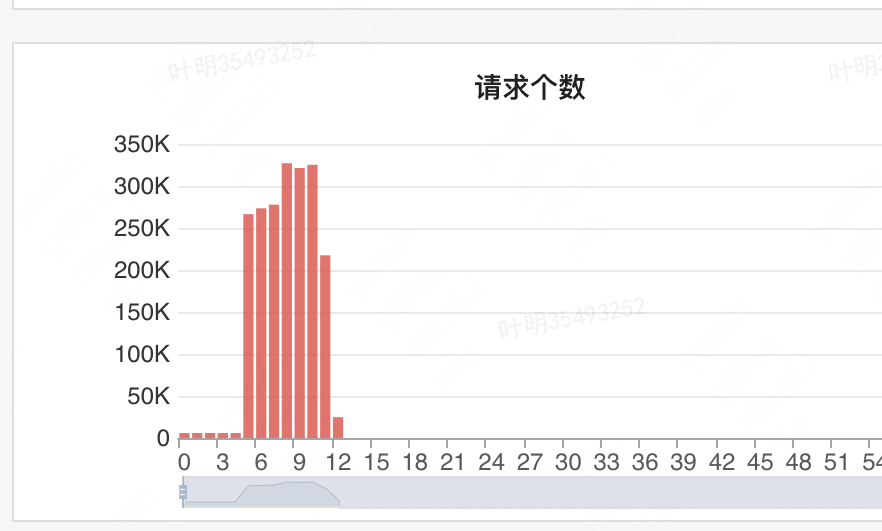
接下来其实还做了进一步的优化:将优化方案中的聚合线程串行执行Aviator和Java脚本改成并行执行Aviator和Java脚本本以为能进一步提升速度,测试下来性能反而下降。后来发现在执行Aviator脚本时候,会进行加锁操作,故实际耗时可能更长。故最终方案是多个聚合线程拉取同一个阻塞队列,聚合线程内部串行执行Aviator和Java脚本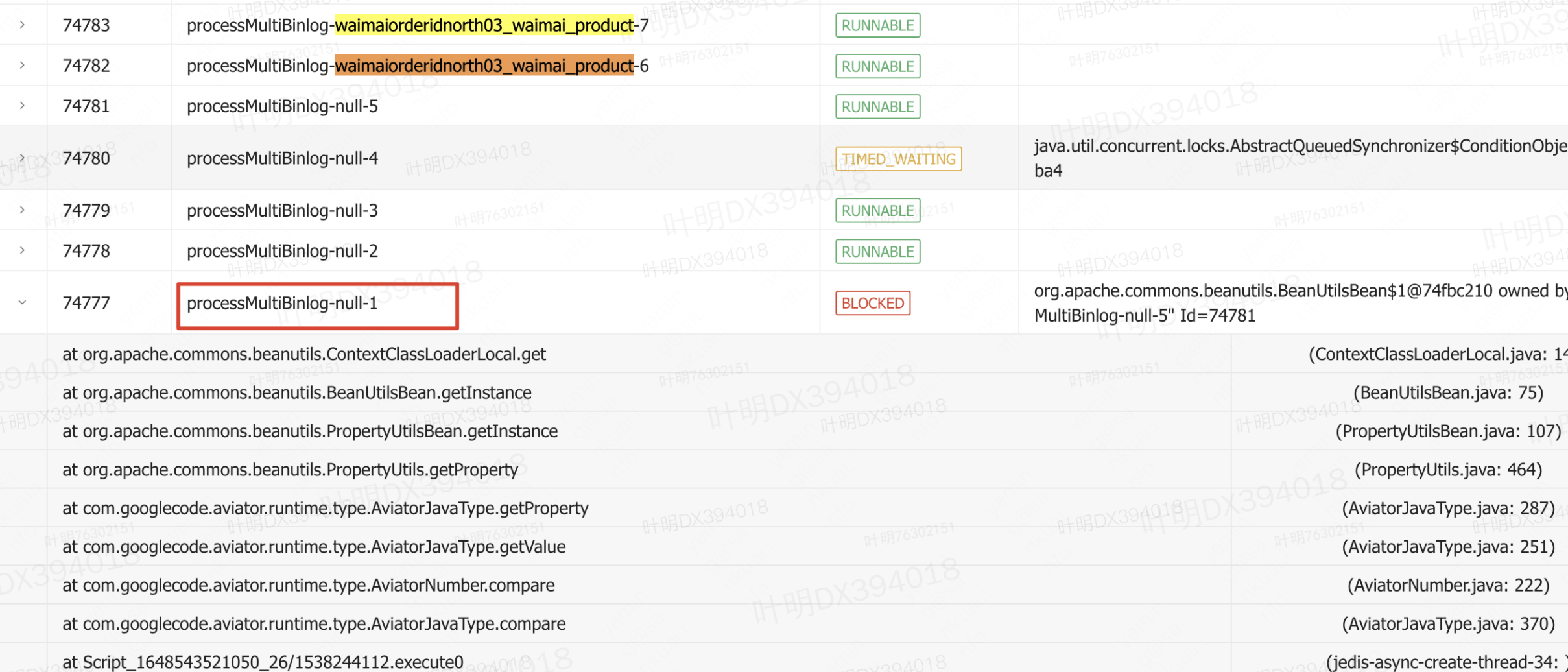
五、思考
一个完整链路的数据处理流程,整体性能主要取决于性能最弱的一环,显然优化思路就是先分通过监控打点或者代码找出性能最弱的一个缓解,然后进行针对性的优化。常见优化方式就就是串行改并行,同步转异步。同时并行修改后,还要考虑到会不会引入锁冲突问题,这个往往容易被忽视。

