下文通过3个案例来叙述JVM GC问题的根因定位和优化方案。
一、CMS background gc导致服务频繁GC排查优化
1.1、现象
10.196.177.28一分钟触发了11次fullgc,查看监控,基本判断是old区达到设置阈值导致的fullgc。奇怪的是GC后old区内存是被回收了,但还是发生了11次fgc。这种情况大概率就是因为 cms background gc 导致的
1.2、排查
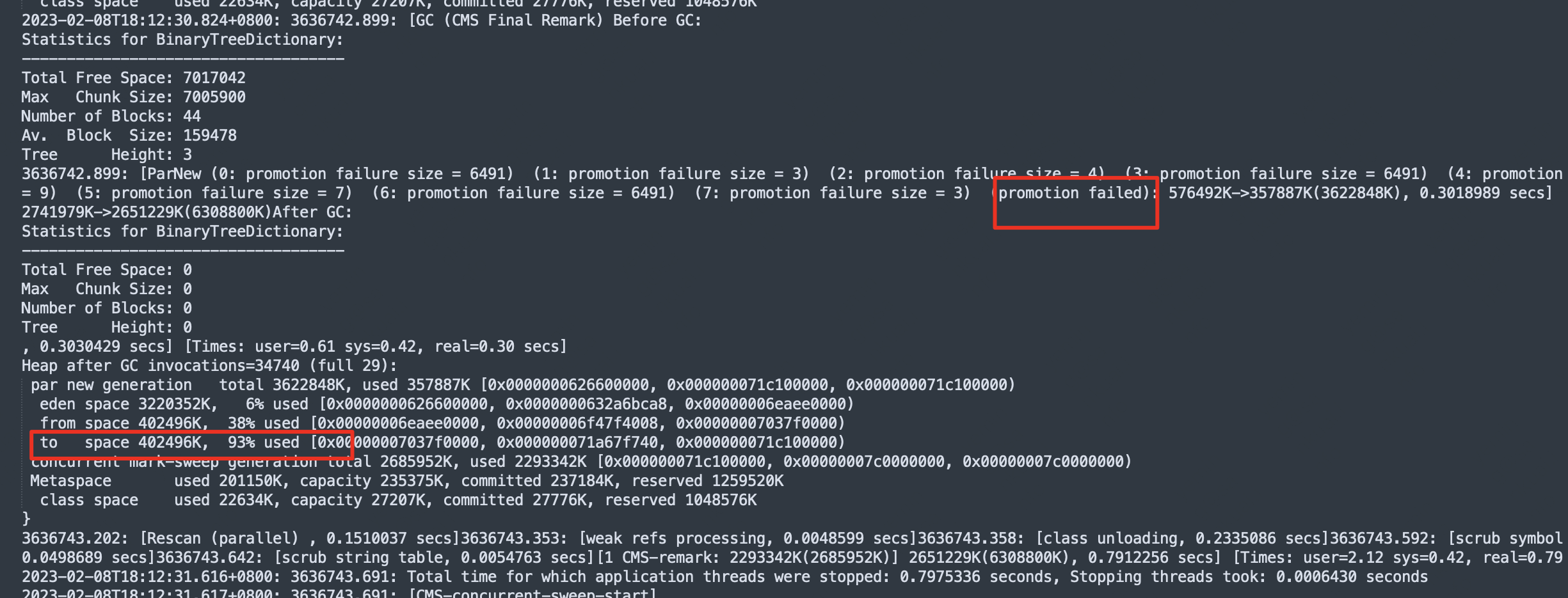 CMS Final Remark 后,发生了一次 promotion failed,由于配置了 CMSScavengeBeforeRemark,在remark之前会进行一次younggc,但是younggc后,to space 不为空(正常younggc后,将eden和from中内存整理后,幸存的对象拷贝到to后,然后from取变成to,内存应该为0的,如下图)。to space 不为空,就是后续触发 gmc backgroud gc的导火索, CMS 的 background collector 每隔 2s 检查一次 GC 触发条件,其中一个条件就是 to space 不为空,这里不再赘述。
CMS Final Remark 后,发生了一次 promotion failed,由于配置了 CMSScavengeBeforeRemark,在remark之前会进行一次younggc,但是younggc后,to space 不为空(正常younggc后,将eden和from中内存整理后,幸存的对象拷贝到to后,然后from取变成to,内存应该为0的,如下图)。to space 不为空,就是后续触发 gmc backgroud gc的导火索, CMS 的 background collector 每隔 2s 检查一次 GC 触发条件,其中一个条件就是 to space 不为空,这里不再赘述。
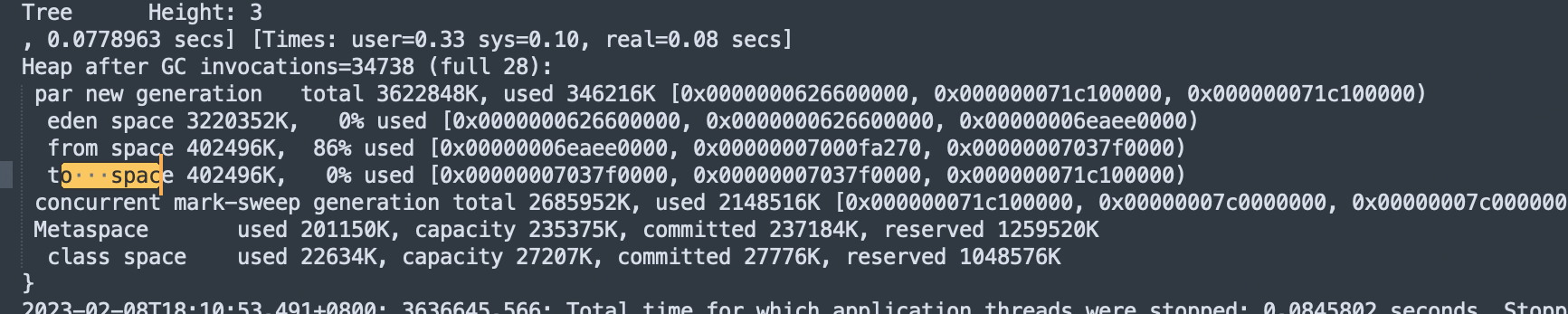 那什么时候结束上述 cms background collector 呢,必须要等到 eden 去空间达到100%之后,然后触发一次 younggc,将to区可用空间重新置为0才能恢复。
那什么时候结束上述 cms background collector 呢,必须要等到 eden 去空间达到100%之后,然后触发一次 younggc,将to区可用空间重新置为0才能恢复。
1.3、优化方案
- 降低 promotion failed 出现概率
- 去掉 -XX:+CMSScavengeBeforeRemark remark之前,不再进行youngcc,不太可取
- -XX:CMSInitiatingOccupancyFraction=80,降低参数阈值,old区保留足够的空间以便能放下young区晋升来的对象。
- 提高 Young GC 的频率,这样即使 to space不为空,由于能快速进行一次youngc也能把 to space清理掉。该方案缺点也很明显,young区过小,会导致很多对象快速进入到 old区,导致fullgc 次数可能会过多
二、大对象导致Fullgc过快问题排查优化
2.1、现象
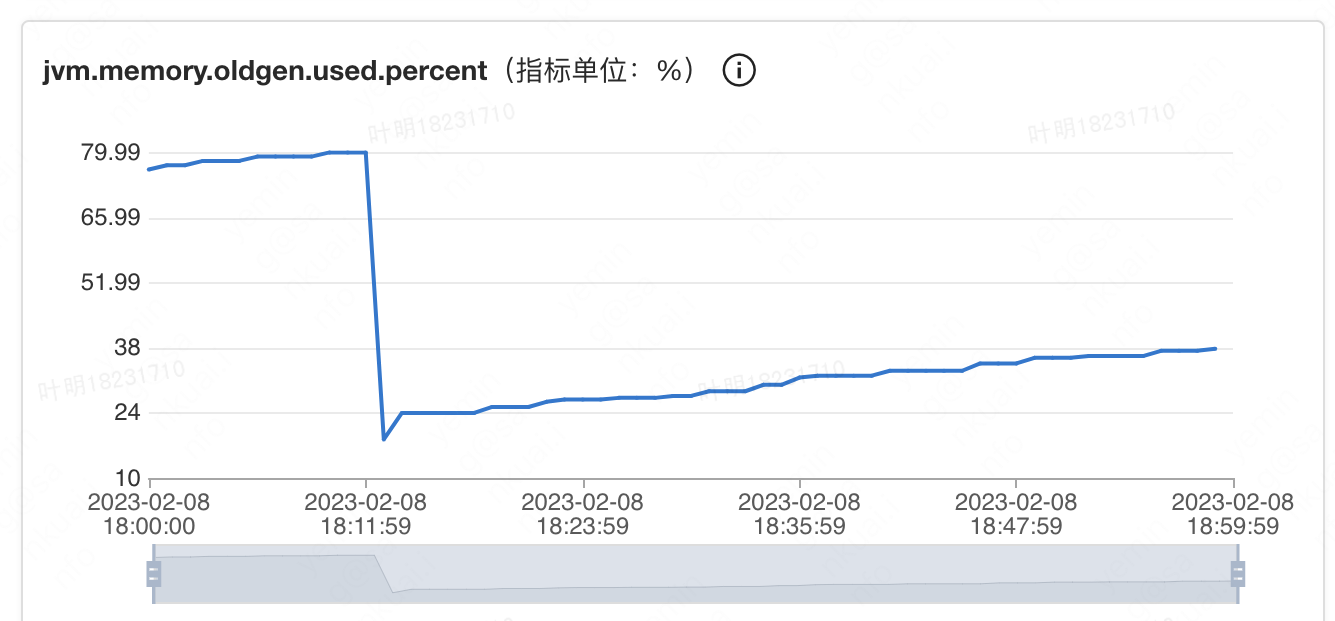
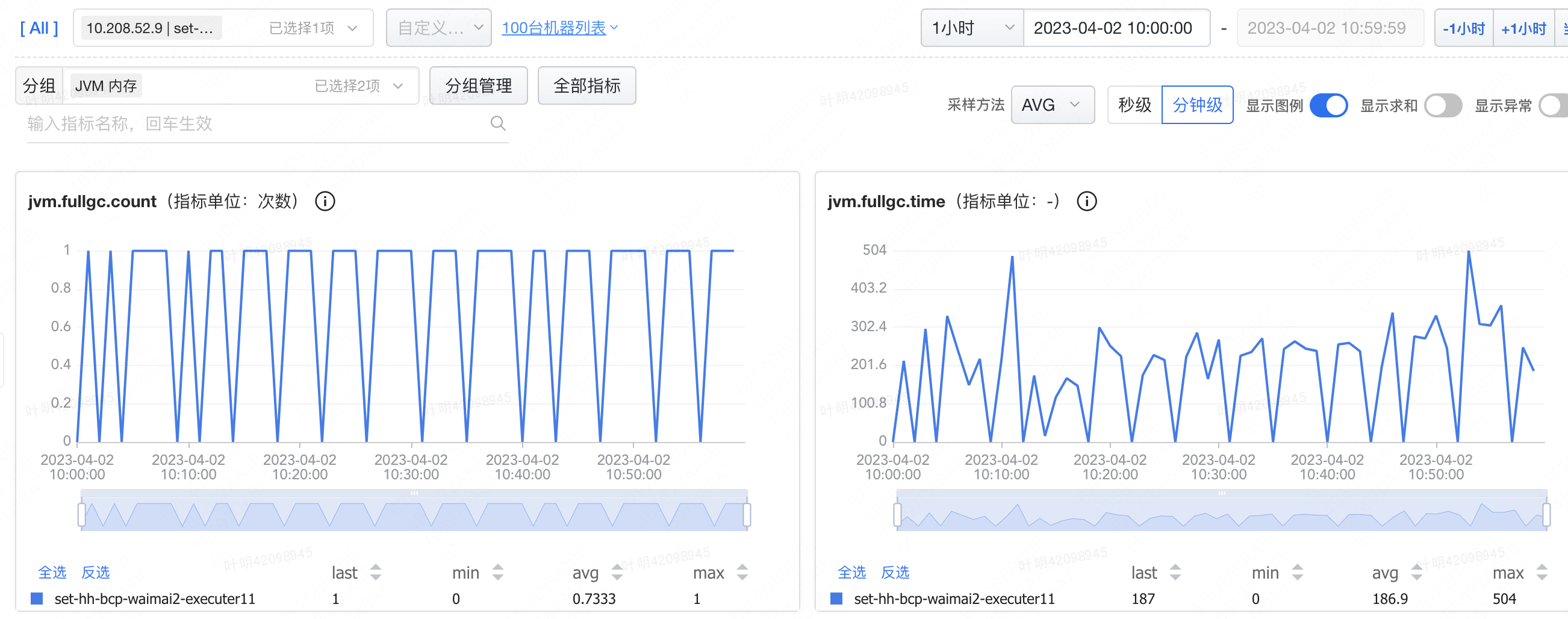
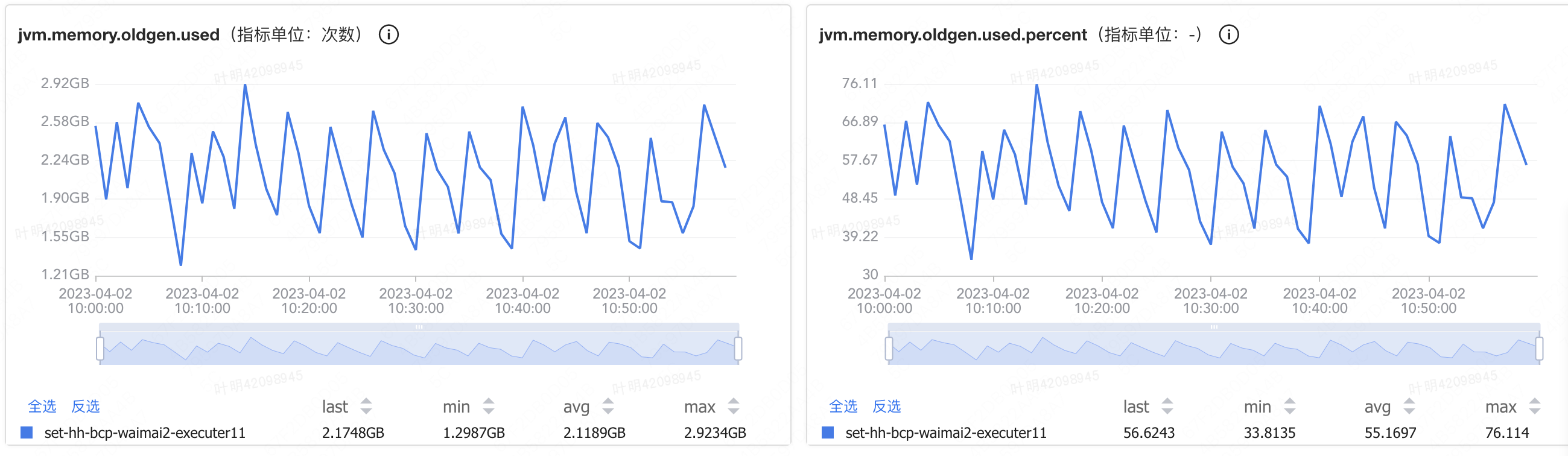
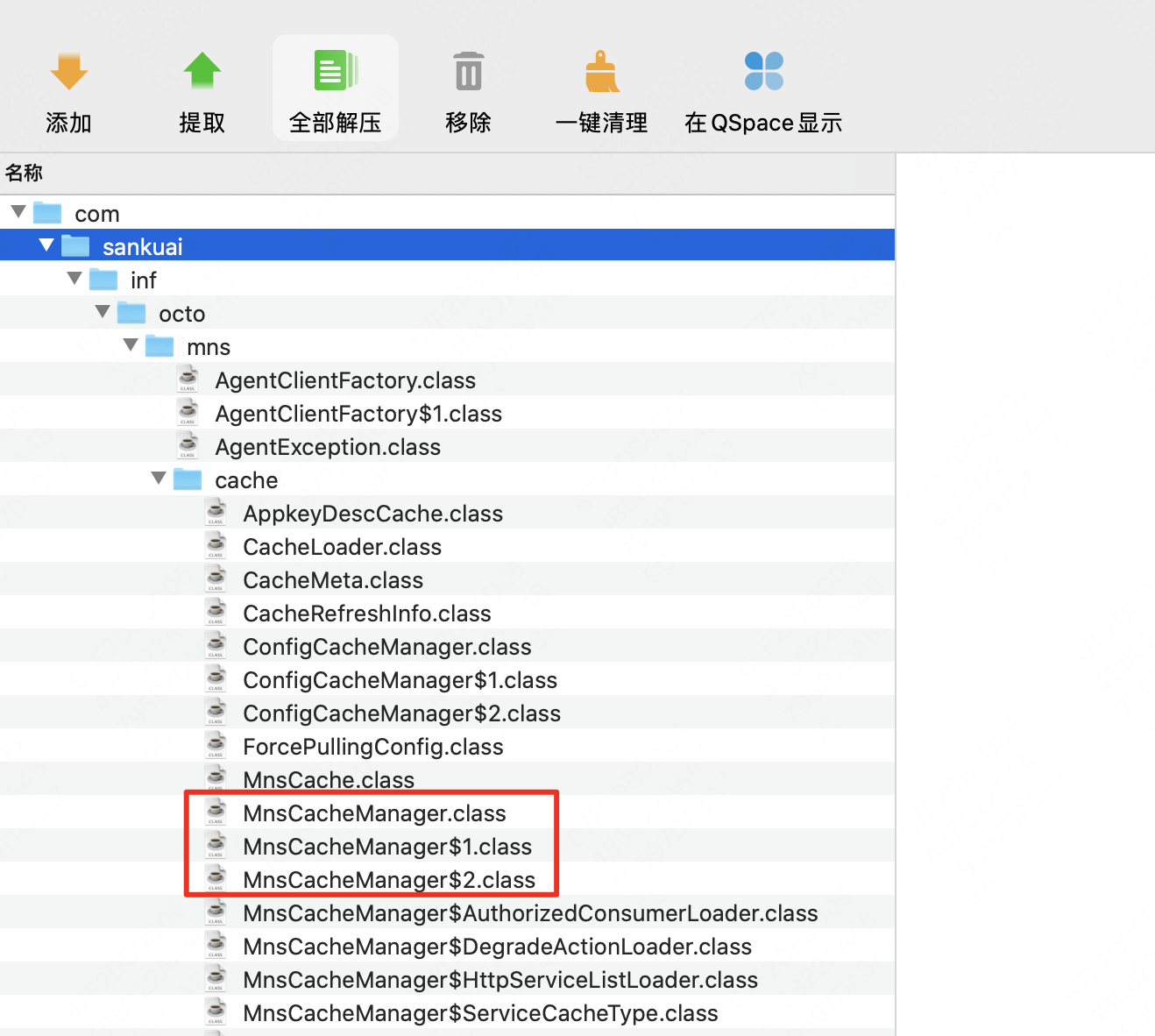
 线上外卖2执行服务一共有接近100台机器,最近频繁收到机器FullGC相关的告警:短时间发生FullGC次数频繁,同时偶发性的FullGC后使用内存>=70。以 10.208.52.9 | set-hh-bcp-waimai2-executer11 这台机器为例,通过观察jvm.fullgc.count指标,该机器平均每分钟都会进行一次FullGC,同时结合观察jvm.memory.olden.used.percent指标,不难判断上述FullGC的原因是olden区使用内存达到阈值。
结合上述指标我们基本可以判断FullGC根因是:系统有大对象生成,同时该大对象生成速度过快,结合偶发性的FullGC后使用内存>=70告警,可以进一步判断该对象的存活时间可能较长,一次FullGC还无法完全释放。
线上外卖2执行服务一共有接近100台机器,最近频繁收到机器FullGC相关的告警:短时间发生FullGC次数频繁,同时偶发性的FullGC后使用内存>=70。以 10.208.52.9 | set-hh-bcp-waimai2-executer11 这台机器为例,通过观察jvm.fullgc.count指标,该机器平均每分钟都会进行一次FullGC,同时结合观察jvm.memory.olden.used.percent指标,不难判断上述FullGC的原因是olden区使用内存达到阈值。
结合上述指标我们基本可以判断FullGC根因是:系统有大对象生成,同时该大对象生成速度过快,结合偶发性的FullGC后使用内存>=70告警,可以进一步判断该对象的存活时间可能较长,一次FullGC还无法完全释放。
2.2、排查
- Dump 外卖2执行服务内存,发现MnsCacheManager对象占用内存较多,为了避免偶发性干扰,线上Dump了较多机器内存,基本都能稳定复现,详情见 Dump列表,基本都是OCTO相关的对象占用内存较大。
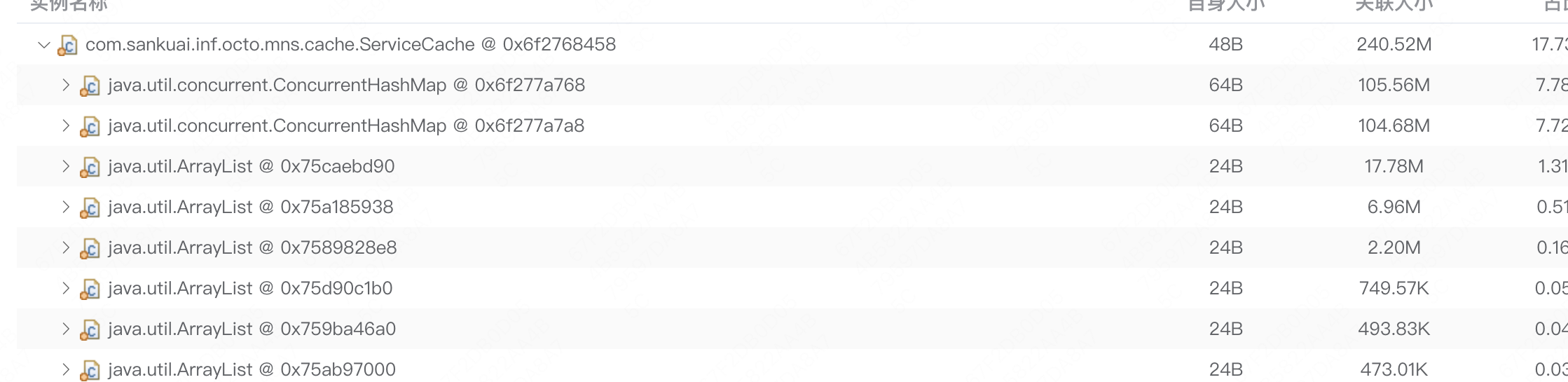
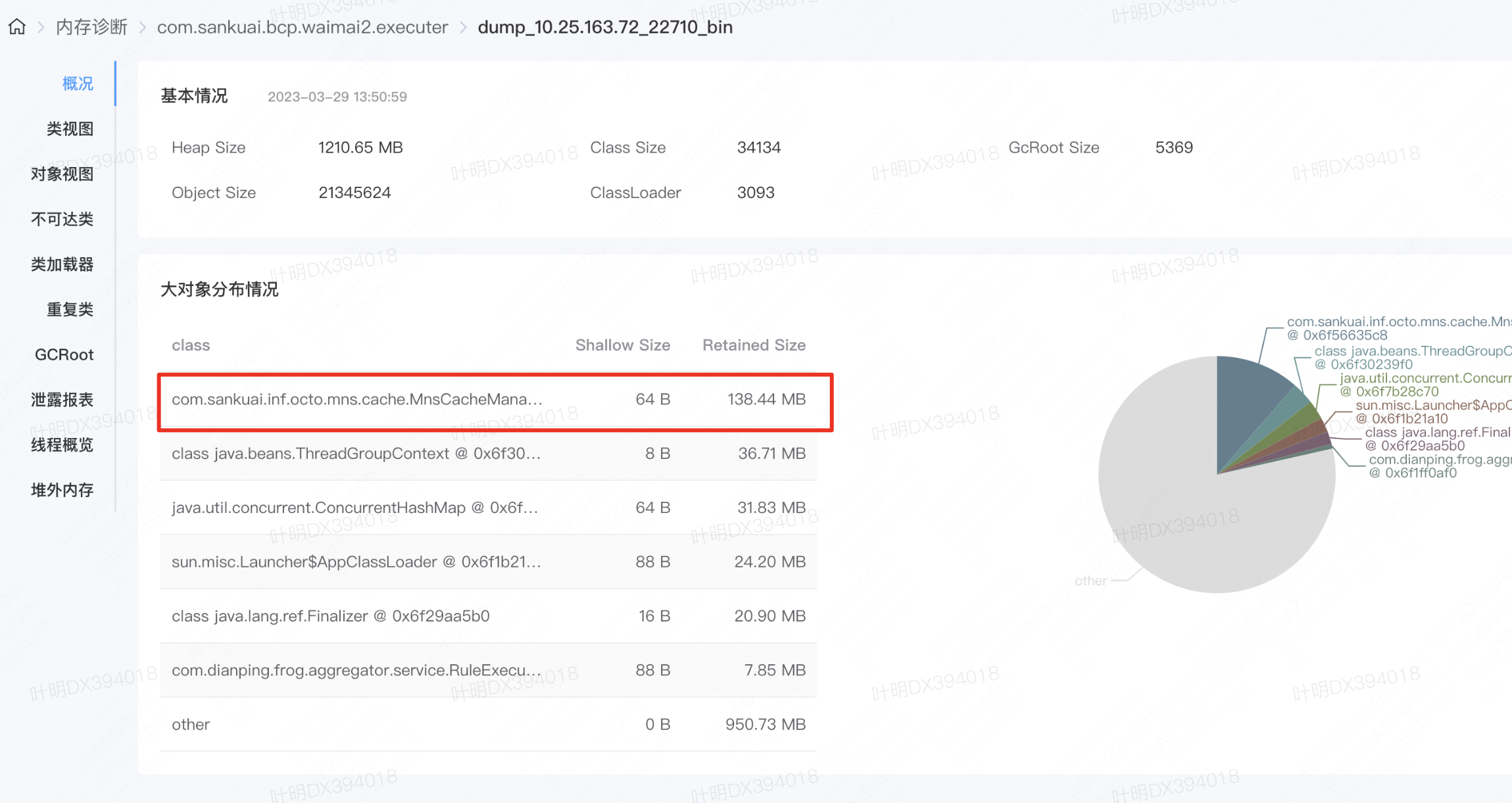
- MnsCacheManager中有两个对象serviceCache,httpServiceCache,其中 defaultUpdateTime = 5,会有一个子线程每5s会全量刷新一次上面两个对象,考虑到外卖2执行服务上运行了很多业务RPC泛化调用脚本,涉及到不少下游业务服务,详情见 Raptor链接。经过和 OCTO 同学 沟通,该对象一共占用200多M内存基本符合调用的下游业务个数。那么大概原因是该对象产生的时间过于频繁导致的(每5s一次),同时由于会有RPC规则使用该对象,一旦RPC执行较慢,导致对象在一次FullGC后无法完全回收。
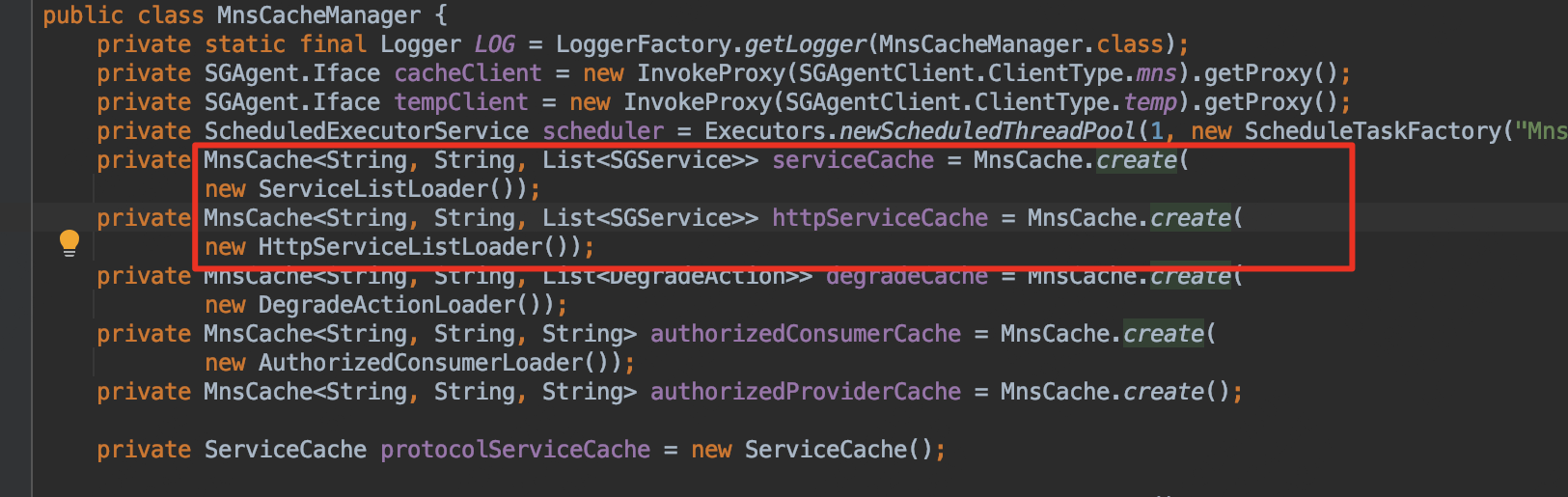
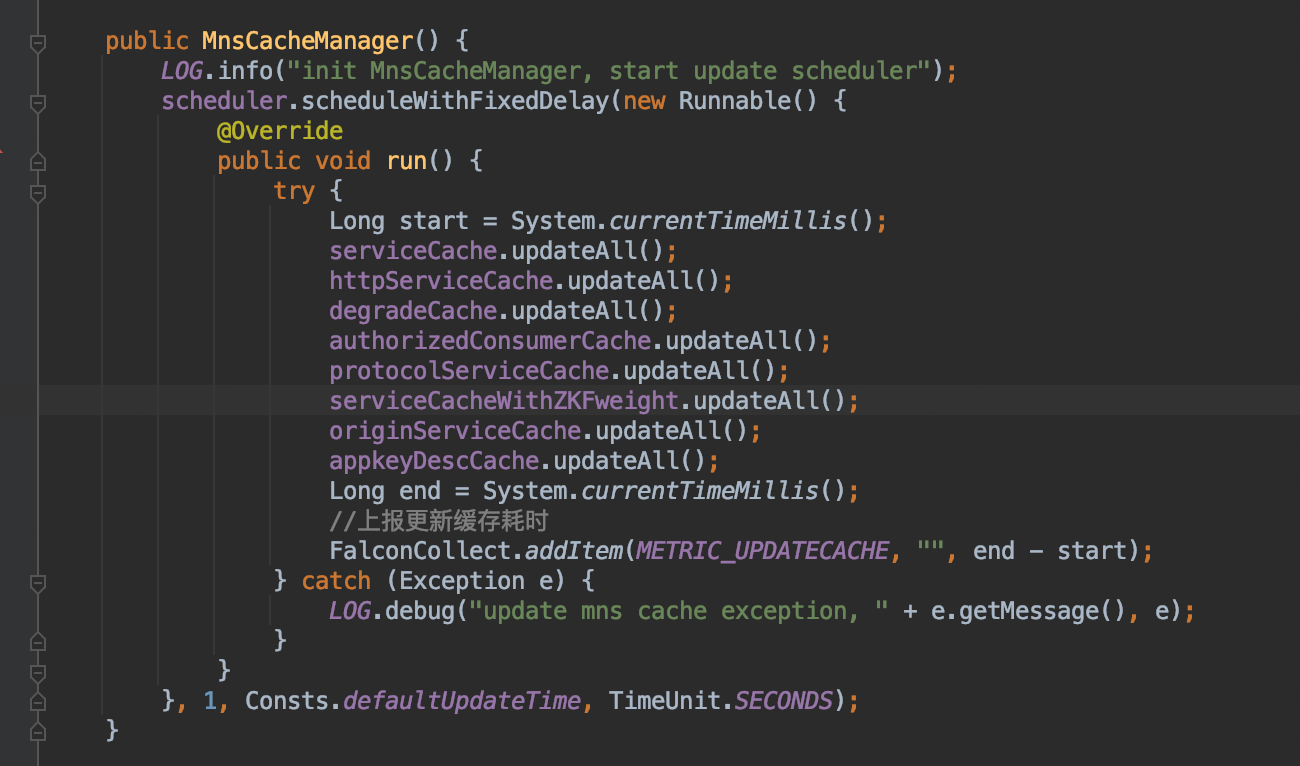
- 确定上述可疑问题后,我们能想到的方案就是修改轮询时间,经过和 确认,OCTO客户端没有提供修改轮询时间的参数,同时 defaultUpdateTime = 5,同时该参数是一个final变量,也无法在启动时候通过反射修改。
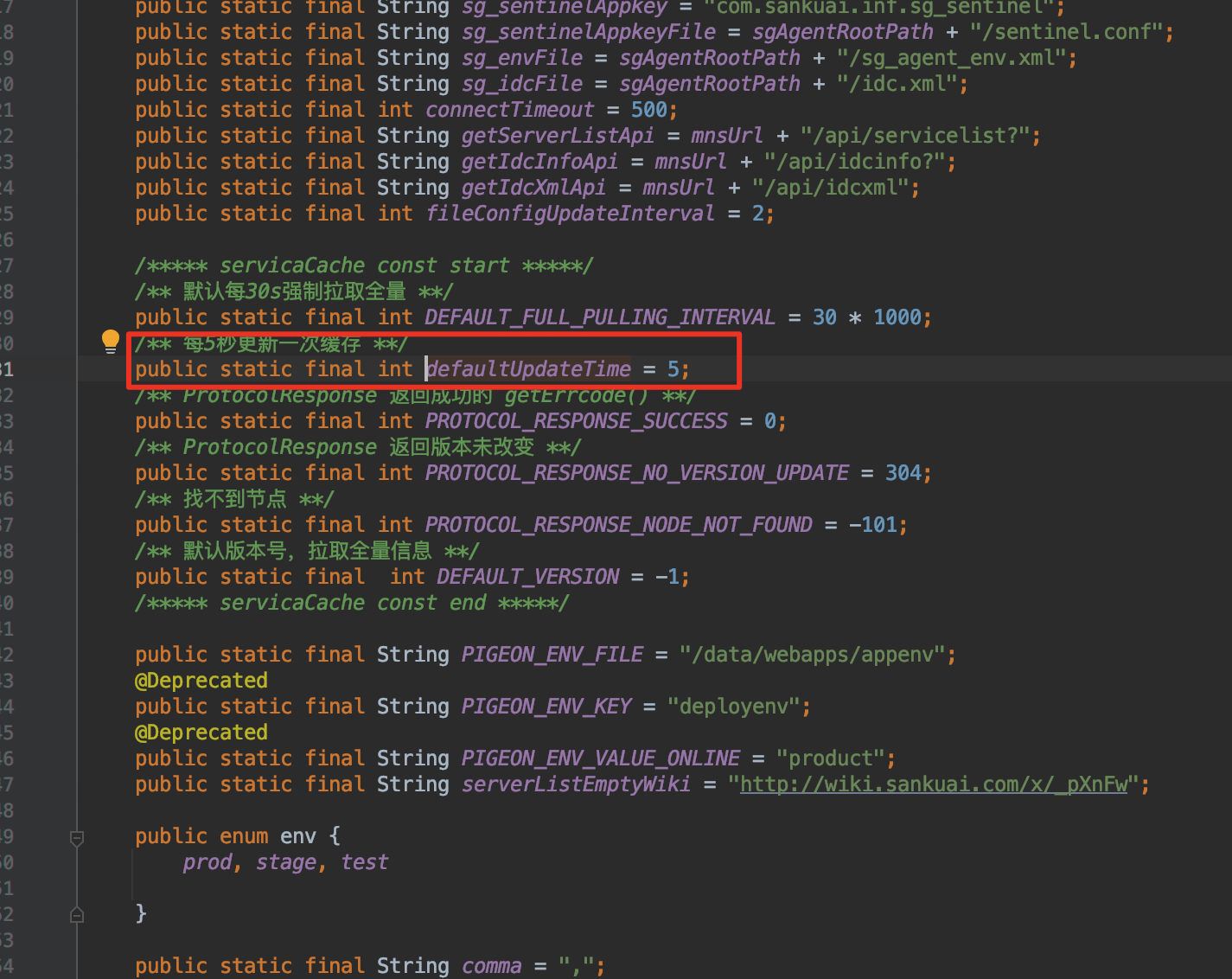
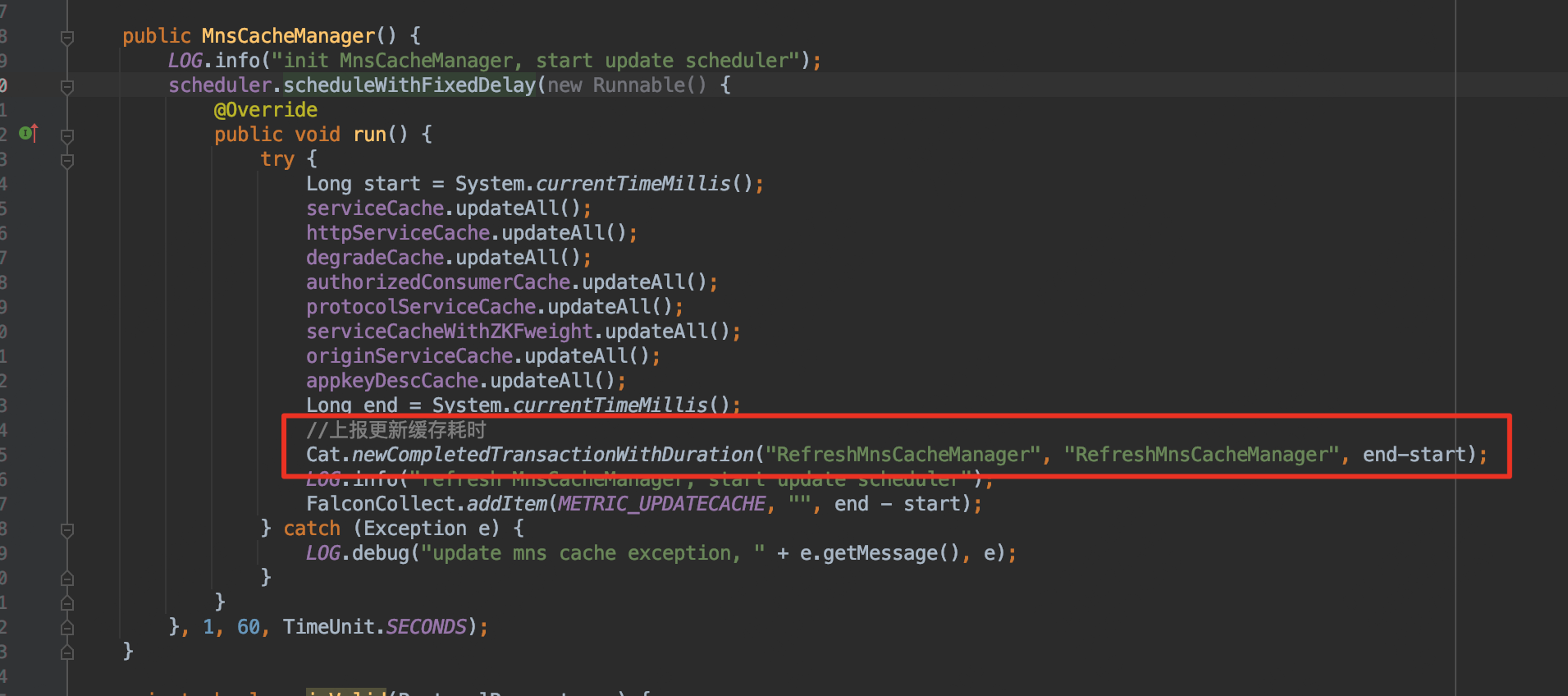
- 于是决定创建一个同类路径同名的 MnsCacheManager,直接修改轮询时间为60s,同时添加方法耗时Transaction打点,便于来观测和验证上述猜测的方法耗时相对较长
- 然后重新编译该类 MnsCacheManager,生成 MnsCacheManager.class和两个匿名内部类,将生成后的该类添加到 mns-invoker-1.12.0.jar 包里面,然后将该 jar 包直接上传到线上一台外卖2执行机器,重新启动进行验证。
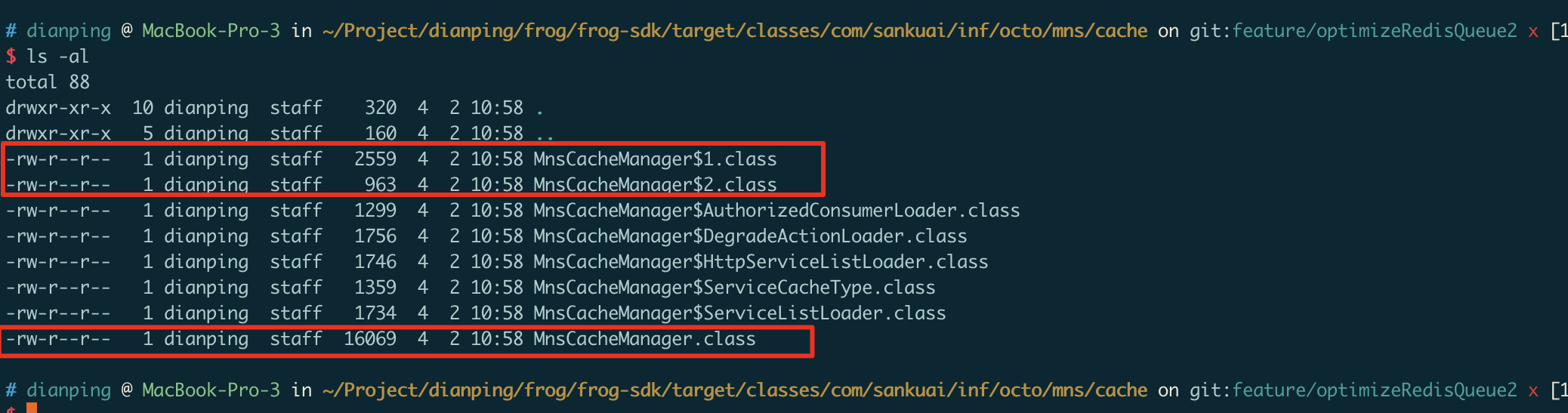
- 重新启动使用经过修改后的 mns-invoker-1.12.0.jar 包的机器,13点18分服务重启后,虽然相对其他服务FullGC还是较为频繁,但和13点18分之前的几乎一分钟进行一次FullGC相比已经有了明显下降。
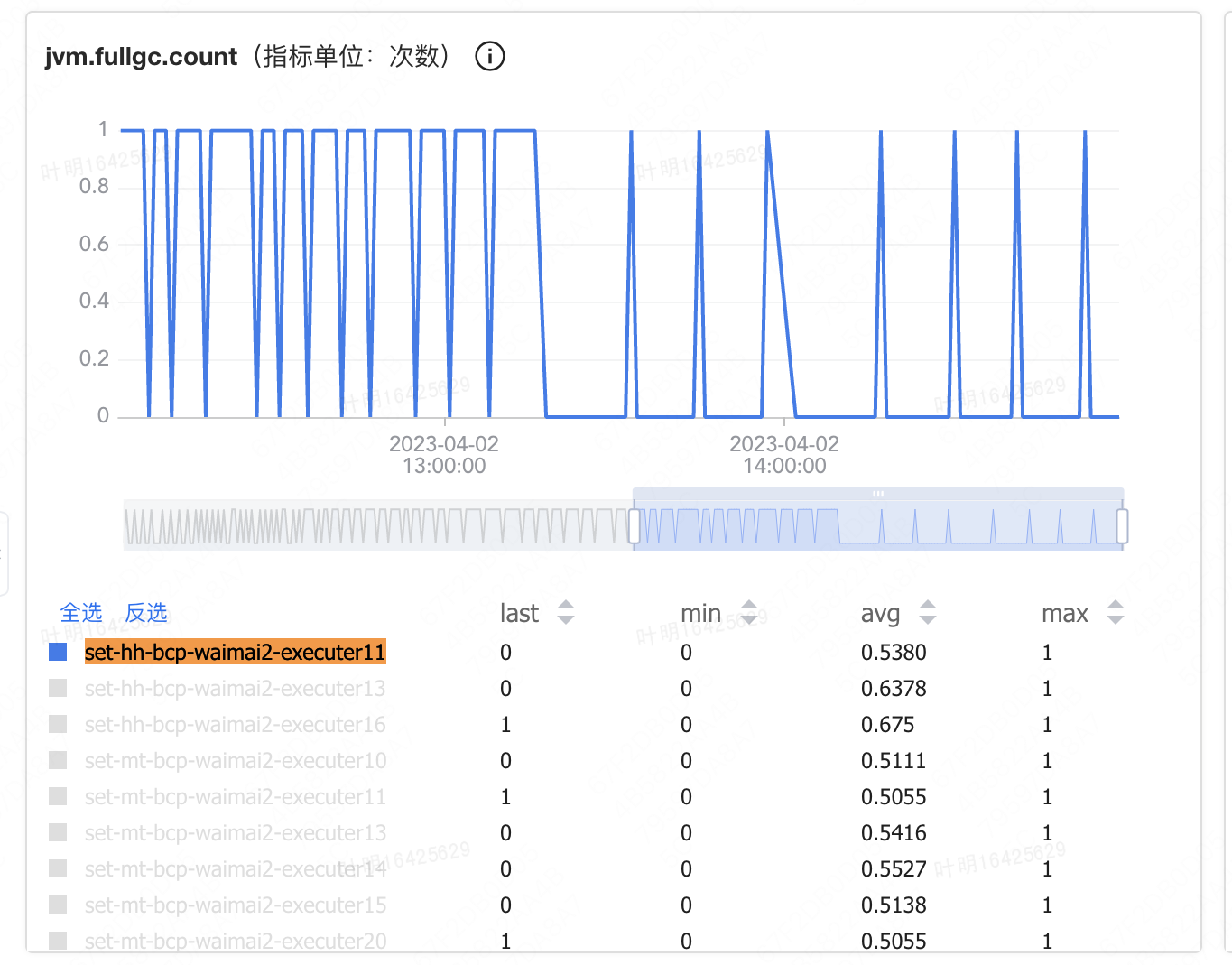 同时观察 Raptor Transaction 报表,已经可以看到 RefreshMnsCacheManager,每60s执行一次,说明我们修改轮询时间的代码生效了。
同时观察 Raptor Transaction 报表,已经可以看到 RefreshMnsCacheManager,每60s执行一次,说明我们修改轮询时间的代码生效了。
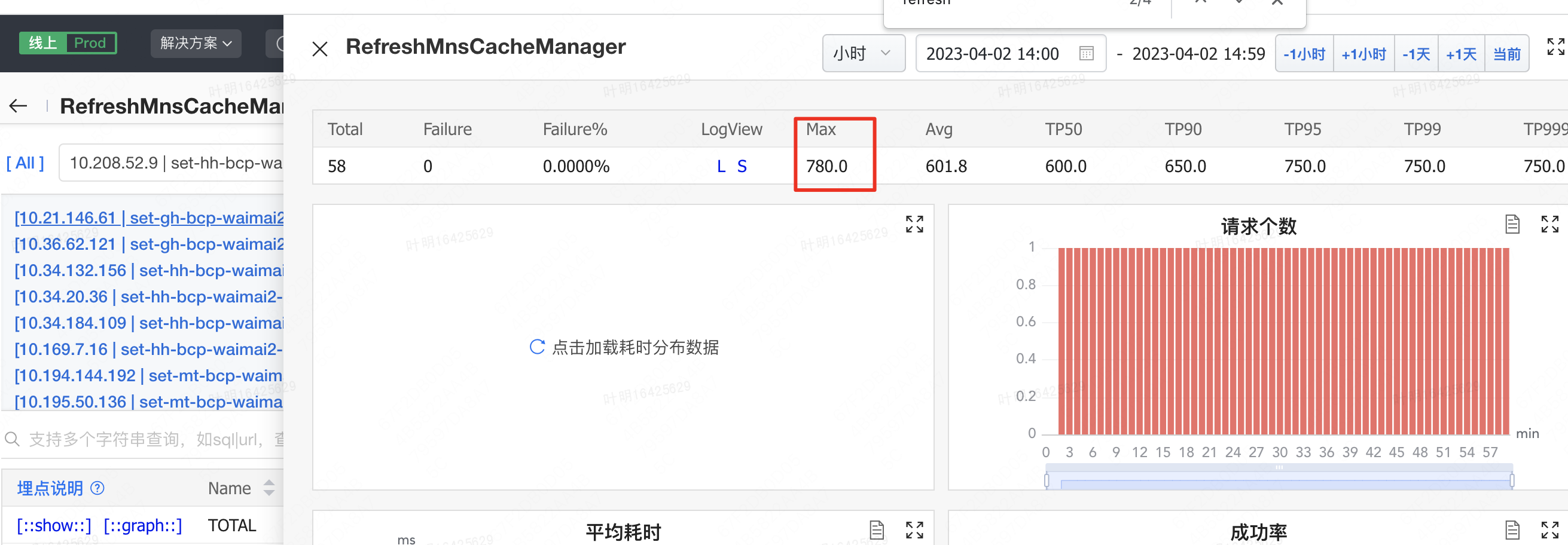
- 同时,为了进一步确认是由于 OCTO 的上述对象无法在YoungGC全部回收,导致对象频繁进入老年代,进一步通过调整JVM启动参数,添加 PrintClassHistogramBeforeFullGC和PrintClassHistogramBeforeAfterGC参数,通过FullGC前后对比来发现哪些对象频繁进入到老年代(我们这个发布的版本是我们修改 MnsCacheManager 类之前的版本,更容易观察OCTO产生的大对象)。
- 通过观察FullGC前后对比,发现OCTO关联的 SGService和ServiceDetail对象,在FullGC前,该对象被回收了几乎一半,这个也说明确实有很多OCTO对象无法在年轻代中被回收,只能晋升到老年代,同时老年代发生了一次FullGC后,还无法完全回收该内存,因为可能存在业务的RPC调用代码会使用上述配置。另外,除OCTO相关对象外,其他占用较多内存的GC前后内存基本没有变化,应该是服务正常运行会缓存一部分配置信息的原因。
下图是FullGC前堆内存分享分布 下图是FullGC后堆内存分享分布
下图是FullGC后堆内存分享分布
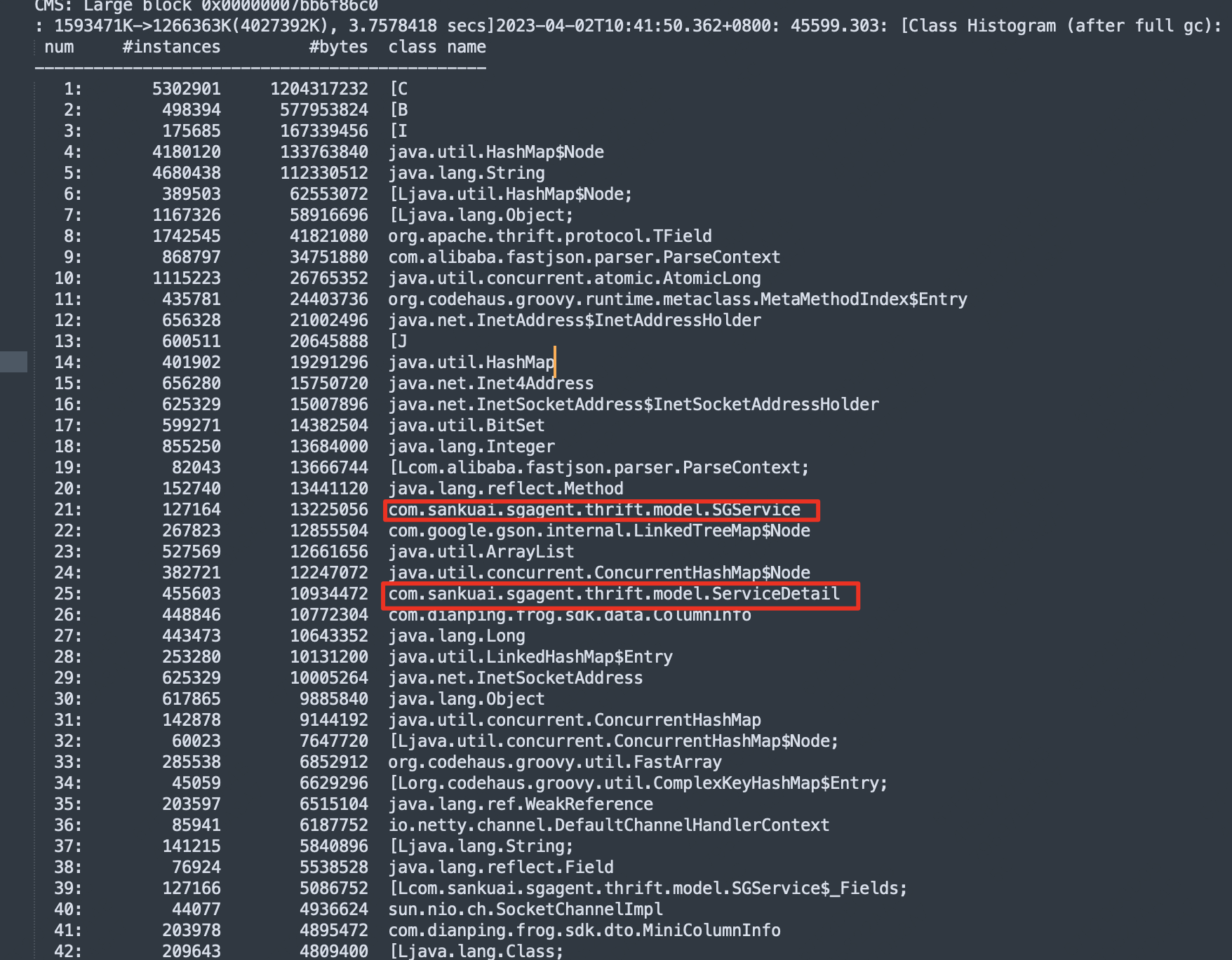
2.3、结论
外卖2执行服务FullGC过快的原因确实是由于 OCTO MnsCacheManager 每5s会全量更新一次缓存导致,由于外卖2执行服务会运行大量配置的RPC泛化调用规则,涉及到较多下游服务,详情见 Raptor链接,导致每5s会产生超过 200M OCTO相关对象。另外由于部分业务规则RPC调用逻辑会使用上述缓存的OCTO配置信息,部分方法执行较慢,导致OCTO上述大对象在一次FullGC后释放不明显,进而加剧了服务FullGC告
2.4、优化
- OCTO侧:希望客户端SDK提供修改MnsCacheManager缓存的轮询频率设置,同时评估下上述对象占用内存有没有减小的可能
- BCP侧:建立业务RPC泛化调用规则耗时监控机制,实时发现长耗时规则,并持续推进业务治理
三、MetaSpace持续增长优化
3.1、现象
BCP规则执行服务运行一般时间就会持续出现Metaspace溢出导致服务持续FGC,但是内存很难释放,最终直至出现OOM
3.2、排查
主要原因如下:
- GroovyClassLoader动态加载脚本:BCP规则执行服务使用GroovyClassLoader动态加载业务10000多个规则校验脚本,脚本变更都会重新加载
- 反射调用:业务部分BCP规则脚本频繁使用反射调用,也会导致MetaSpace增加较快
3.3、优化
- 业务层面拆分集群,将10000多个Java规则拆分到不同集群,并增加JVM最大MetaSpace配置
- 配置Dsun.reflect.inflationThreshold=2147483647,用于设置反射对象的膨胀阈值。具体来说,可以控制通过反射生成字节码。(该值表示 反射调用多少次 才开始生成字节码) 。当把该参数这是int 最大值时,说明永不生成字节码。参考 MetaSpace OOM
If you are on a Oracle JVM then you would only need to set: -Dsun.reflect.inflationThreshold=2147483647 If you are on IBM JVM, then you would need to set: -Dsun.reflect.inflationThreshold=0 - XX:SoftRefLRUPolicyMSPerMB=7000,控制Java软引用对象是否被回收,SoftReference对象到底在GC的时候要不要回收是通过如下的一个公式来判定的:
这个公式的意思就是说:clock - timestamp <= freespace * SoftRefLRUPolicyMSPerMB - clock - timestamp 代表了一个软引用对象他有多久没被访问过了
- freespace 代表JVM中的空闲内存空间
- SoftRefLRUPolicyMSPerMB 代表每一MB空闲内存空间可以允许SoftReference对象存活多久
所以一旦这个参数设置为0之后,直接导致clock - timestamp <= freespace * SoftRefLRUPolicyMSPerMB这个公式的右半边是0,就导致所有的软引用对象,比如JVM生成的那些奇怪的Class对象,刚创建出来就可能被一次Young
最终排查下来还是因为 SoftRefLRUPolicyMSPerMB设置成0,导致线上Dump发现有很多SoftReference类对象,可以将这个参数适当调大一点即可

