之前我们介绍了Provider启动时候向注册中心注册服务
Dubbo源码学习二(服务注册),Consumer启动时候向注册中心订阅服务Dubbo源码学习三(服务引用),本文我们就来看下Consumer端和Provider是怎么通信的。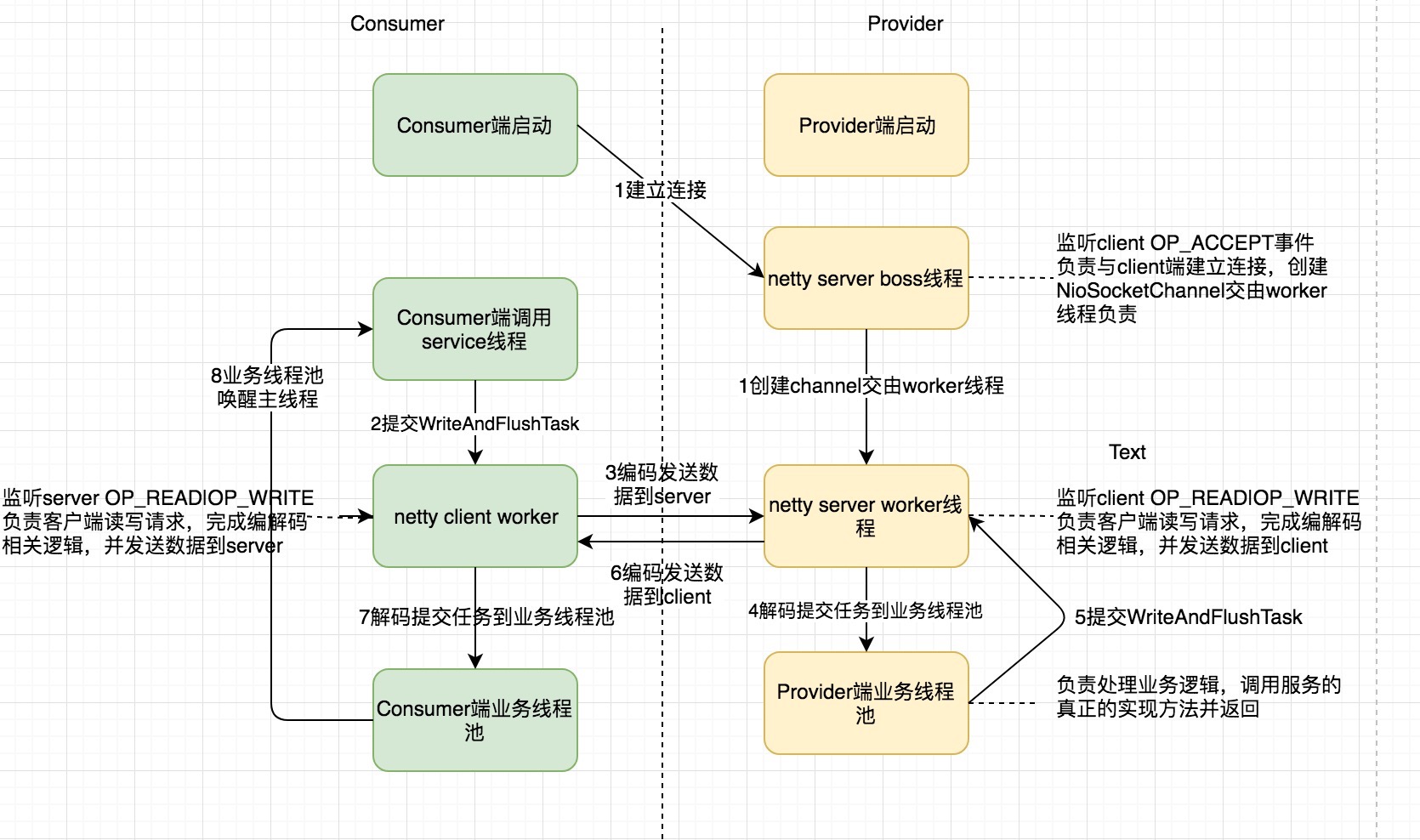
Consumer
public static void main(String[] args) {
DemoService demoService = (DemoService) context.getBean("demoService"); // get remote service proxy
String hello = demoService.sayHello("world");
System.out.println(hello); // get result
}Consumer部分主要包含以下逻辑:
- 主线程里面寻找合适的invoker经由netty发送request生成future对象。
- netty工作线程对Consumer端request进行编码然后发送
- netty工作线程对Provider端 response进行解码然后提交任务到业务自定义线程池
- 业务自定义线程池对response进行相应处理,设置1中的future状态为done状态
- 主线程future返回
我们主要看下上述1,2,3,4几个过程
主线程发送request
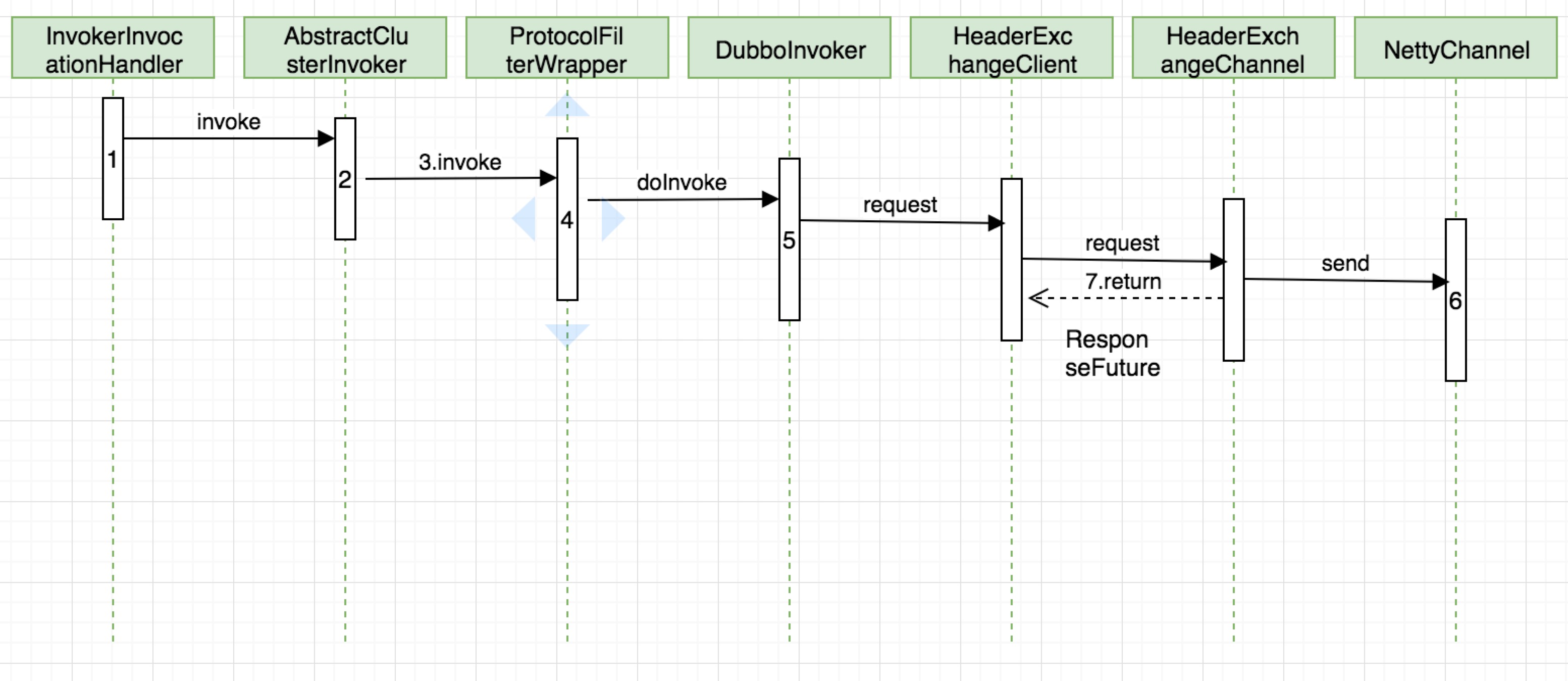 上图是主线程发送request的时序图,接下来会对从1-7的几个过程逐一分析。过程1在上一篇文章中,我们知道demoService在Consumer端通过JDK动态代理,把Invoker转换成为客户端需要的接口。然后调用sayHello方法时,经由动态代理调用到InvokerInvocationHandler.invoke()方法
上图是主线程发送request的时序图,接下来会对从1-7的几个过程逐一分析。过程1在上一篇文章中,我们知道demoService在Consumer端通过JDK动态代理,把Invoker转换成为客户端需要的接口。然后调用sayHello方法时,经由动态代理调用到InvokerInvocationHandler.invoke()方法
InvokerInvocationHandler
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
RpcInvocation invocation = new RpcInvocation(method, args);
return invoker.invoke(invocation).recreate();
}过程2主要是调用AbstractClusterInvoker的invoke方法,该方法会根据directory获取缓存的invokers(提供服务的Provider有多少个就有多少个invoker),然后通过调用子类
FailoverClusterInvoker的doInvoke方法,该方法会根据loadBalance选取合适的invoker进行调用,调用失败还会进行重试,默认最多重试3次
AbstractClusterInvoker
@Override
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
LoadBalance loadbalance = null;
List<Invoker<T>> invokers = list(invocation);
if (invokers != null && !invokers.isEmpty()) {
loadbalance = ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(invokers.get(0).getUrl()
.getMethodParameter(RpcUtils.getMethodName(invocation), Constants.LOADBALANCE_KEY, Constants.DEFAULT_LOADBALANCE));
}
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
return doInvoke(invocation, invokers, loadbalance);
}
protected List<Invoker<T>> list(Invocation invocation) throws RpcException {
List<Invoker<T>> invokers = directory.list(invocation);
return invokers;
}过程3FailoverClusterInvoker.doInvoke
==>InvokerWrapper.invoke==>InvokerWrapper.invoke==>ProtocolFilterWrapper
过程4用到了责任链设计模式,这里可以添加自定的filter对调用前后进行拦截,完成一些通用的逻辑。默认情况有ConsumerContextFilter,FutureFilter,MonitoFilter,依次调用其
invoke方法
ProtocolFilterWrapper
private static <T> Invoker<T> buildInvokerChain(final Invoker<T> invoker, String key, String group) {
Invoker<T> last = invoker;
List<Filter> filters = ExtensionLoader.getExtensionLoader(Filter.class).getActivateExtension(invoker.getUrl(), key, group);
if (!filters.isEmpty()) {
for (int i = filters.size() - 1; i >= 0; i--) {
final Filter filter = filters.get(i);
final Invoker<T> next = last;
last = new Invoker<T>() {
@Override
public Class<T> getInterface() {
return invoker.getInterface();
}
@Override
public URL getUrl() {
return invoker.getUrl();
}
@Override
public boolean isAvailable() {
return invoker.isAvailable();
}
@Override
public Result invoke(Invocation invocation) throws RpcException {
return filter.invoke(next, invocation);
}
@Override
public void destroy() {
invoker.destroy();
}
@Override
public String toString() {
return invoker.toString();
}
};
}
}
return last;
}过程5生成调用的RpcInvocation(其中包含方法名,参数类型,参数值以及一些附加的属性),并根据需要支持方法异步调用或者callback调用
DubboInvoker
@Override
protected Result doInvoke(final Invocation invocation) throws Throwable {
RpcInvocation inv = (RpcInvocation) invocation;
final String methodName = RpcUtils.getMethodName(invocation);
inv.setAttachment(Constants.PATH_KEY, getUrl().getPath());
inv.setAttachment(Constants.VERSION_KEY, version);
ExchangeClient currentClient;
if (clients.length == 1) {
currentClient = clients[0];
} else {
currentClient = clients[index.getAndIncrement() % clients.length];
}
try {
boolean isAsync = RpcUtils.isAsync(getUrl(), invocation);
boolean isAsyncFuture = RpcUtils.isGeneratedFuture(inv) || RpcUtils.isFutureReturnType(inv);
boolean isOneway = RpcUtils.isOneway(getUrl(), invocation);
int timeout = getUrl().getMethodParameter(methodName, Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
if (isOneway) {
boolean isSent = getUrl().getMethodParameter(methodName, Constants.SENT_KEY, false);
currentClient.send(inv, isSent);
RpcContext.getContext().setFuture(null);
return new RpcResult();
} else if (isAsync) {
ResponseFuture future = currentClient.request(inv, timeout);
// For compatibility
FutureAdapter<Object> futureAdapter = new FutureAdapter<>(future);
RpcContext.getContext().setFuture(futureAdapter);
Result result;
if (isAsyncFuture) {
// register resultCallback, sometimes we need the asyn result being processed by the filter chain.
result = new AsyncRpcResult(futureAdapter, futureAdapter.getResultFuture(), false);
} else {
result = new SimpleAsyncRpcResult(futureAdapter, futureAdapter.getResultFuture(), false);
}
return result;
} else {
RpcContext.getContext().setFuture(null);
return (Result) currentClient.request(inv, timeout).get();
}
} catch (TimeoutException e) {
throw new RpcException(RpcException.TIMEOUT_EXCEPTION, "Invoke remote method timeout. method: " + invocation.getMethodName() + ", provider: " + getUrl() + ", cause: " + e.getMessage(), e);
} catch (RemotingException e) {
throw new RpcException(RpcException.NETWORK_EXCEPTION, "Failed to invoke remote method: " + invocation.getMethodName() + ", provider: " + getUrl() + ", cause: " + e.getMessage(), e);
}
}过程6channel.writeAndFlush(message)这个channel是NioSocketChannel(netty源码研究二(请求处理)是客户端用来发送消息的)
NettyChannel
@Override
public void send(Object message, boolean sent) throws RemotingException {
super.send(message, sent);
boolean success = true;
int timeout = 0;
try {
ChannelFuture future = channel.writeAndFlush(message);
if (sent) {
timeout = getUrl().getPositiveParameter(Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
success = future.await(timeout);
}
Throwable cause = future.cause();
if (cause != null) {
throw cause;
}
} catch (Throwable e) {
throw new RemotingException(this, "Failed to send message " + message + " to " + getRemoteAddress() + ", cause: " + e.getMessage(), e);
}
if (!success) {
throw new RemotingException(this, "Failed to send message " + message + " to " + getRemoteAddress()
+ "in timeout(" + timeout + "ms) limit");
}
}AbstractChannelHandlerContext
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}上述channel.writeAndFlush(message)最终会对调用到AbstractChannelHandlerContext的execute方法,该方法会判断当前线程是否在一个eventLoop里面,如果不在就新开启一个eventLoop线程或者eventLoop线程已经开启就放到队列里面。显然该线程是Consumer调用线程,显然不是eventLoop线程,此时会生成WriteAndFlushTask任务丢到队列里面。
过程7调用DefaultFuture构造函数创建一个future并返回,然后主线程调用阻塞在future.get()方法。
HeaderExchangeChannel
@Override
public ResponseFuture request(Object request, int timeout) throws RemotingException {
if (closed) {
throw new RemotingException(this.getLocalAddress(), null, "Failed to send request " + request + ", cause: The channel " + this + " is closed!");
}
// create request.
Request req = new Request();
req.setVersion(Version.getProtocolVersion());
req.setTwoWay(true);
req.setData(request);
DefaultFuture future = new DefaultFuture(channel, req, timeout);
try {
channel.send(req);
} catch (RemotingException e) {
future.cancel();
throw e;
}
return future;
}可以看到DefaultFuture类缓存了连个全局的Map,构造函数里面,将请求的id和和对应的future,channel关联起来保存到Map里面,后续接受Provider端的response会用到。
DefaultFuture
private static final Map<Long, Channel> CHANNELS = new ConcurrentHashMap<Long, Channel>();
private static final Map<Long, DefaultFuture> FUTURES = new ConcurrentHashMap<Long, DefaultFuture>();
public DefaultFuture(Channel channel, Request request, int timeout) {
this.channel = channel;
this.request = request;
this.id = request.getId();
this.timeout = timeout > 0 ? timeout : channel.getUrl().getPositiveParameter(Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
// put into waiting map.
FUTURES.put(id, this);
CHANNELS.put(id, channel);
}Netty工作线程处理request并发送
上面一个流程会将request提交给netty EventLoop线程,下面看下eventLoop线程怎么处理的。
NettyClient
bootstrap.handler(new ChannelInitializer() {
@Override
protected void initChannel(Channel ch) throws Exception {
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyClient.this);
ch.pipeline()//.addLast("logging",new LoggingHandler(LogLevel.INFO))//for debug
.addLast("decoder", adapter.getDecoder())
.addLast("encoder", adapter.getEncoder())
.addLast("handler", nettyClientHandler);
}
});Consumer端Netty启动时候添加了以上3个ChannelHandler,注意以上
adapter.getEncoder()是ChannelOutboundHandler,adapter.getDecoder()是ChannelInboundHandler,nettyClientHandler两者都是。这里我们只需要知道接受主线程传过来的req会用到ChannelOutboundHandler,并且依次调用nettyClientHandler,adapter.getEncoder();接受服务端发过来的response会用到ChannelInboundHandler,并且依次调用
adapter.getDecoder(),nettyClientHandler,两者顺序正好相反
接下来我们就看下netty编码encode过程
NettyCodecAdapter.InternalEncoder
private class InternalEncoder extends MessageToByteEncoder {
@Override
protected void encode(ChannelHandlerContext ctx, Object msg, ByteBuf out) throws Exception {
org.apache.dubbo.remoting.buffer.ChannelBuffer buffer = new NettyBackedChannelBuffer(out);
Channel ch = ctx.channel();
NettyChannel channel = NettyChannel.getOrAddChannel(ch, url, handler);
try {
codec.encode(channel, buffer, msg);
} finally {
NettyChannel.removeChannelIfDisconnected(ch);
}
}
}InternalEncoder继承netty自带的MessageToByteEncoder,netty工作线程在对request进行编码过程中,会调用到上述encode方法。上述方法先通过Netty原生Channel拿到dubbo自身封装的NettyChannel,然后调用
DubboCountCodec.encode==>ExchangeCodec.encode==>ExchangeCodec.
encodeRequest
ExchangeCodec
protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
Serialization serialization = getSerialization(channel);
// header.
byte[] header = new byte[HEADER_LENGTH];
// set magic number.
Bytes.short2bytes(MAGIC, header);
// set request and serialization flag.
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
if (req.isTwoWay()) header[2] |= FLAG_TWOWAY;
if (req.isEvent()) header[2] |= FLAG_EVENT;
// set request id.
Bytes.long2bytes(req.getId(), header, 4);
// encode request data.
int savedWriteIndex = buffer.writerIndex();
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
if (req.isEvent()) {
encodeEventData(channel, out, req.getData());
} else {
encodeRequestData(channel, out, req.getData(), req.getVersion());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
bos.flush();
bos.close();
int len = bos.writtenBytes();
checkPayload(channel, len);
Bytes.int2bytes(len, header, 12);
// write
buffer.writerIndex(savedWriteIndex);
buffer.writeBytes(header); // write header.
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
//header固定16个字节,每个字节内容如下
2byte magic:类似java字节码文件里的魔数,用来判断是不是dubbo协议的数据包。魔数是常量0xdabb
1byte 的消息标志位:16-20序列id,21 event,22 two way,23请求或响应标识
1byte 状态,当消息类型为响应时,设置响应状态。24-31位。状态位, 设置请求响应状态,dubbo定义了一些响应的类型。具体类型见com.alibaba.dubbo.remoting.exchange.Response
8byte 消息ID,long类型,32-95位。每一个请求的唯一识别id(由于采用异步通讯的方式,用来把请求request和返回的response对应上)
4byte 消息长度,96-127位。消息体 body 长度, int 类型,即记录Body Content有多少个字节。
}
//消息体的内容如下:
1、dubbo版本号
2、invoke的路径
3、invoke的provider端暴露的服务的版本号
4、调用的方法名称
5、参数类型描述符
6、遍历请求参数值并编码
7、dubbo请求的attachments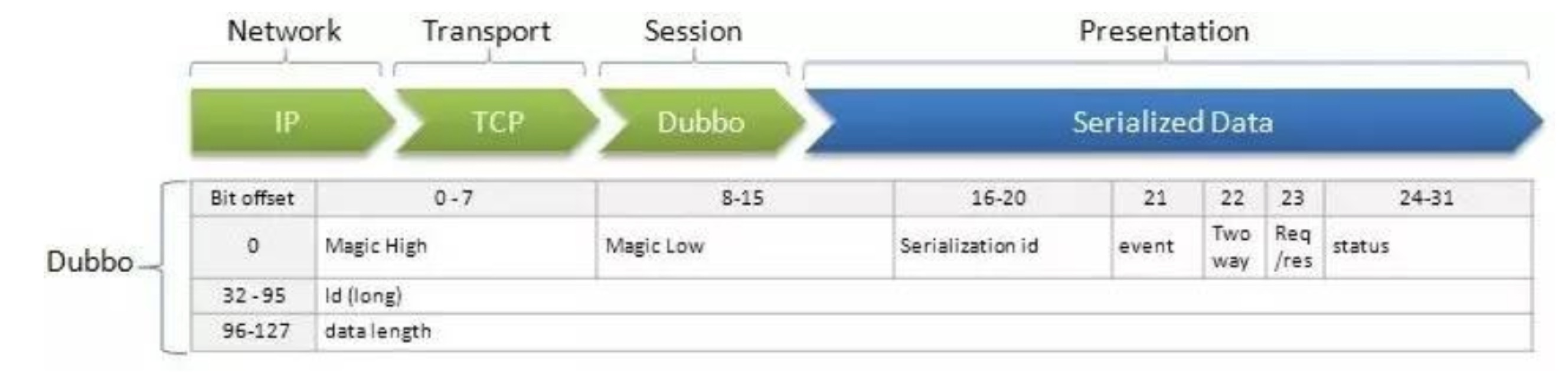 上述代码是dubbo的编码过程,dubbo通过上述代码自定义通信协议,每条dubbo消息包含header和body(包含方法参数值等信息),header固定16个字节。buffer先将writeIndex设置为header长度,然后将body req.getData()序列化写进buffer。最后重新设置writeIndex=0,将header写入buffer。
上述代码是dubbo的编码过程,dubbo通过上述代码自定义通信协议,每条dubbo消息包含header和body(包含方法参数值等信息),header固定16个字节。buffer先将writeIndex设置为header长度,然后将body req.getData()序列化写进buffer。最后重新设置writeIndex=0,将header写入buffer。
最后WriteAndFlushTask类,ctx.invokeFlush() flush刷新buffer就会提交消息到Provider端
public void write(AbstractChannelHandlerContext ctx, Object msg, ChannelPromise promise) {
super.write(ctx, msg, promise);
ctx.invokeFlush();
}用Netty作为传输框架时,图中的Client和Server分别对应NettyClient和NettyServer,在创建的时候会指定encoder和decoder完成对象的编码和解码。Dubbo协议默认DubboCountCodec为编解码器,该类的成员DubboCodec封装了Dubbo协议的编解码逻辑,同时完成对象的序列化或反序列化。
Netty工作线程接收response
上述发送request对应的客户端ChannelOutboundHandler,接收response对应ChannelInboundHandler,Consumer端接收到Provider端的response会依次经由adapter.getDecoder(),nettyClientHandler进行处理。这里有一点比较麻烦,Consumer收到Provider response时通过InternalDecoder进行解码(对应的Provider接收Consumer的request),InternalDecoder每次收到的数据包不一定是完整的dubbo协议包,也有可能是多个dubbo协议包。这里就是tcp传输所谓的黏包和拆包问题。黏包/拆包问题是由于底层的TCP无法理解上层的业务数据,所以底层是无法保证数据包不被拆分和分组的,只能通过上层的应用协议栈来设计解决。一般有以下几种方案来解决
- 消息定长,如果不够,用空格来补
- 在包尾增加回车换行符来分割
- 将消息分为消息头和消息体,消息头中包含消息体的长度。
Dubbo采用了第三种方案,我们上面讲过dubbo协议的header是定长的16字节,最后4字节表示消息体长度。
InternalDecoder
protected void decode(ChannelHandlerContext ctx, ByteBuf input, List<Object> out) throws Exception {
ChannelBuffer message = new NettyBackedChannelBuffer(input);
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
Object msg;
int saveReaderIndex;
try {
// decode object.
do {
saveReaderIndex = message.readerIndex();
try {
msg = codec.decode(channel, message);
} catch (IOException e) {
throw e;
}
if (msg == Codec2.DecodeResult.NEED_MORE_INPUT) {
message.readerIndex(saveReaderIndex);
break;
} else {
//is it possible to go here ?
if (saveReaderIndex == message.readerIndex()) {
throw new IOException("Decode without read data.");
}
if (msg != null) {
out.add(msg);
}
}
} while (message.readable());
} finally {
NettyChannel.removeChannelIfDisconnected(ctx.channel());
}
}ExchangeCodec
protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) throws IOException {
// check magic number.
if (readable > 0 && header[0] != MAGIC_HIGH
|| readable > 1 && header[1] != MAGIC_LOW) {
int length = header.length;
if (header.length < readable) {
header = Bytes.copyOf(header, readable);
buffer.readBytes(header, length, readable - length);
}
for (int i = 1; i < header.length - 1; i++) {
if (header[i] == MAGIC_HIGH && header[i + 1] == MAGIC_LOW) {
buffer.readerIndex(buffer.readerIndex() - header.length + i);
header = Bytes.copyOf(header, i);
break;
}
}
return super.decode(channel, buffer, readable, header);
}
// check length.
if (readable < HEADER_LENGTH) {
return DecodeResult.NEED_MORE_INPUT;
}
// get data length.
int len = Bytes.bytes2int(header, 12);
checkPayload(channel, len);
int tt = len + HEADER_LENGTH;
if (readable < tt) {
return DecodeResult.NEED_MORE_INPUT;
}
// limit input stream.
ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len);
try {
return decodeBody(channel, is, header);
} finally {
if (is.available() > 0) {
try {
if (logger.isWarnEnabled()) {
logger.warn("Skip input stream " + is.available());
}
StreamUtils.skipUnusedStream(is);
} catch (IOException e) {
logger.warn(e.getMessage(), e);
}
}
}
}上述方法以及后续DubboCountCodec.decode和ExchangeCodec.decode方法大致逻辑如下:
- 发送过来的buffer的可读字节数小于header长度或者小于header+消息体body的长度,直接返回NEED_MORE_INPUT,并设置message.readerIndex(saveReaderIndex);
- 满足上述规则,直接经过反序列化解析出消息体,添加到List
ByteToMessageDecoder
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
CodecOutputList out = CodecOutputList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
first = cumulation == null;
if (first) {
cumulation = data;
} else {
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= discardAfterReads) {
// We did enough reads already try to discard some bytes so we not risk to see a OOME.
// See https://github.com/netty/netty/issues/4275
numReads = 0;
discardSomeReadBytes();
}
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
fireChannelRead(ctx, out, size);
out.recycle();
}
} else {
ctx.fireChannelRead(msg);
}
}如果发生tcp半包问题,回到父类channelRead方法,因为我们之前设置把readIndex复位,cumulation还是可以读的,所以cumulation数据会缓存不会清空,等待下一个dubbo协议包。并且此时int size = out.size()=0,也不会触发后续的fireChannelRead方法。可以看到后续的dubbo包传输过来后,因为first为false,会合并之前缓存的buffer,这样就解决了tcp半包问题。
对于tcp黏包问题,InternalDecoder本身会while(message.readable())来判断消息是否可读,会持续读取buffer,解析出一个msg就添加到list,如果发生半包问题,就进行上面半包处理逻辑。
上述消息解码后,会交由NettyClientHandler的channelRead方法来处理
NettyClientHandler
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
try {
handler.received(channel, msg);
} finally {
NettyChannel.removeChannelIfDisconnected(ctx.channel());
}
}最终调用到AllChannelHandler.received方法,该方法会创建一个
ChannelEventRunnable,然后交由自定义的业务线程池来处理。
AllChannelHandler
@Override
public void received(Channel channel, Object message) throws RemotingException {
ExecutorService cexecutor = getExecutorService();
try {
cexecutor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
//TODO A temporary solution to the problem that the exception information can not be sent to the opposite end after the thread pool is full. Need a refactoring
//fix The thread pool is full, refuses to call, does not return, and causes the consumer to wait for time out
if(message instanceof Request && t instanceof RejectedExecutionException){
Request request = (Request)message;
if(request.isTwoWay()){
String msg = "Server side(" + url.getIp() + "," + url.getPort() + ") threadpool is exhausted ,detail msg:" + t.getMessage();
Response response = new Response(request.getId(), request.getVersion());
response.setStatus(Response.SERVER_THREADPOOL_EXHAUSTED_ERROR);
response.setErrorMessage(msg);
channel.send(response);
return;
}
}
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}业务自定义线程池对response进行相应处理
经过ChannelEventRunnable.run==>DecodeHandler.received==>HeaderExchangeHandler.received==>HeaderExchangeHandler.handleResponse==>DefaultFuture.received
DefaultFuture
public static void received(Channel channel, Response response) {
try {
DefaultFuture future = FUTURES.remove(response.getId());
if (future != null) {
future.doReceived(response);
} else {
logger.warn("The timeout response finally returned at "
+ (new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date()))
+ ", response " + response
+ (channel == null ? "" : ", channel: " + channel.getLocalAddress()
+ " -> " + channel.getRemoteAddress()));
}
} finally {
CHANNELS.remove(response.getId());
}
}
private void doReceived(Response res) {
lock.lock();
try {
response = res;
if (done != null) {
done.signal();
}
} finally {
lock.unlock();
}
if (callback != null) {
invokeCallback(callback);
}
}我们之前在主线程里面缓存了request.getId()对应的future和channel,这里response.getId()获取的是和request对应一样的id,所以能获取到之前缓存的future,并设置response,然后通过done.signal()来通知被阻塞的主线程。(这里针对同步调用过程)最后删除id关联的之前缓存的future和channel。
调用service主线程返回
之前调用demoService.sayHello(“world”)的主线程阻塞在DefaultFuture.get方法,之前通过done.signal()会唤醒阻塞在done.await的主线程,并返回服务端结果。
DefaultFuture
public Object get(int timeout) throws RemotingException {
if (timeout <= 0) {
timeout = Constants.DEFAULT_TIMEOUT;
}
if (!isDone()) {
long start = System.currentTimeMillis();
lock.lock();
try {
while (!isDone()) {
done.await(timeout, TimeUnit.MILLISECONDS);
if (isDone() || System.currentTimeMillis() - start > timeout) {
break;
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
if (!isDone()) {
throw new TimeoutException(sent > 0, channel, getTimeoutMessage(false));
}
}
return returnFromResponse();
}Provider
Provider端Netty bossGroup线程接受Consumer端发过来的参数,然后交由netty工作线程来处理,这个过程主要是解码request,同上面Consumer端解码response的过程基本一致。解码完成后,交由工作线程进行后续处理。以下分别对上述两个过程进行分析
netty工作线程解码
netty工作线程经由InternalDecoder.decode解码request,然后经由NettyServerHandler.channelRead==>HeartbeatHandler.received==>AllChannelHandler.received,创建一个ChannelEventRunnable到工作线程池,这个过程和上面Consumer解码Provider返回的response几乎一样,这里不过多赘述
dubbo自定义线程池后续处理
经由ChannelEventRunnable.run==>DecodeHandler.received==>HeaderExchangeHandler.handleRequest
HeaderExchangeHandler
void handleRequest(final ExchangeChannel channel, Request req) throws RemotingException {
CompletableFuture<Object> future = handler.reply(channel, msg);
if (future.isDone()) {
res.setStatus(Response.OK);
res.setResult(future.get());
channel.send(res);
return;
}上述handler.reply会调用DubboProtocol.requestHandler.reply方法,该方法根据传过来的Invocation获取到对应的serviceKey,然后从一开始启动过程缓存的Map<String, Exporter<?>> exporterMap exporterMap中获取对应的invoker,这个invoker又会经过ProtocolFilterWrapper中的一系列filter最终调用到DelegateProviderMetaDataInvoker.invoke方法,最终通过反射调用到真正的实现类对应的方法并返回结果。如果是同步调用方法,上面future.isDone返回true,channel.send(res),最终会对调用到AbstractChannelHandlerContext的write方法,之前说过该方法会判断当前线程是不是在nioEventLoop里面,显然当前线程是dubbo自定义的线程,不在nioEvenloop里面,就会创建一个WriteAndFlushTask任务丢到Evenloop所在的netty工作线程里面
netty server工作线程
上一个过程把任务提交到netty server工作线程,然后经过NettyServerHandler.write,InternalEncoder.encode编码后,最后flush就将response发送给Consumer。
总结
可以看到,dubbo整个通信过程中,涉及到很多不同的线程,大致有以下几种线程,按照调用时序如下
- Consumer端调用service线程
- Netty client worker线程
- Netty server boss线程
- Netty server worker线程
- Provider自定义线程池
- Consumer端自定义线城池
本身对于异步编程,都没有同步调用看起来那么舒服,dubbo中又有这么多不同的线程进行交互,所以就更容易摸不着头脑了。我们下面再来以上述线程的发生时间先后梳理下整个过程。
- Consumer端启动过程中请求与Provider端建立连接,Netty server boss线程接受OP_ACCEPT事件,并生成对应的NioSocketChannel,这个channel后续读写请求交由某个Netty server worker线程处理
- 首先Consumer端有个线程调用service某个方法(web应用一般是tomcat线程),然后提交一个WriteAndFlushTask到Netty client worker线程
- Netty client worker线程对方法传过来的参数进行编码等其他操作然后flush就发送给Provider端
- Netty server worker线程接受Consumer的request,然后进行解码,解码完成后,交由Provider端自定义的业务线程池处理
- Provider端自定义业务线程池接受解码后的参数,然后调用指定服务的真实实现方法,并将结果封装到WriteAndFlushTask到Netty server worker线程。
- Netty server worker线程将provider端服务处理的结果进行编码,然后writeAndFlush发送到Consumer端。
- Consumer端Netty client worker线程对response进行解码,然后提交一个任务到Consumer端自定义的业务线程池。
- Consumer端业务线程池处理相关逻辑,然后通知Consumer端调用service方法的线程(如果是同步方法则唤醒被阻塞的线程)。
- Consumer端调用service的线程获取最终的结果。
注意上述Consumer端和Provider都有一个业务线程池,这个是不能少的,有些同学可能会觉得把任务直接交给worker线程来做不就行了吗,然而并不能这样。因为worker线程主要是用来做编解码的一些与业务无关的耗时很短的逻辑,对于Provider端来说,服务的真正实现的方法可能会耗时比较长;对于Consumer端来说,可能还要支持某些callBack方法,耗时也可能比较长,所以上述步骤5和8是不能少的。

