zebra是一个基于JDBC API协议上开发出的高可用、高性能的数据库访问层解决方案。类似阿里的tddl,zebra是一个smart客户端,提供了诸如动态配置、监控、读写分离、分库分表等功能。下图是zebra的整体架构图
zebra整体架构
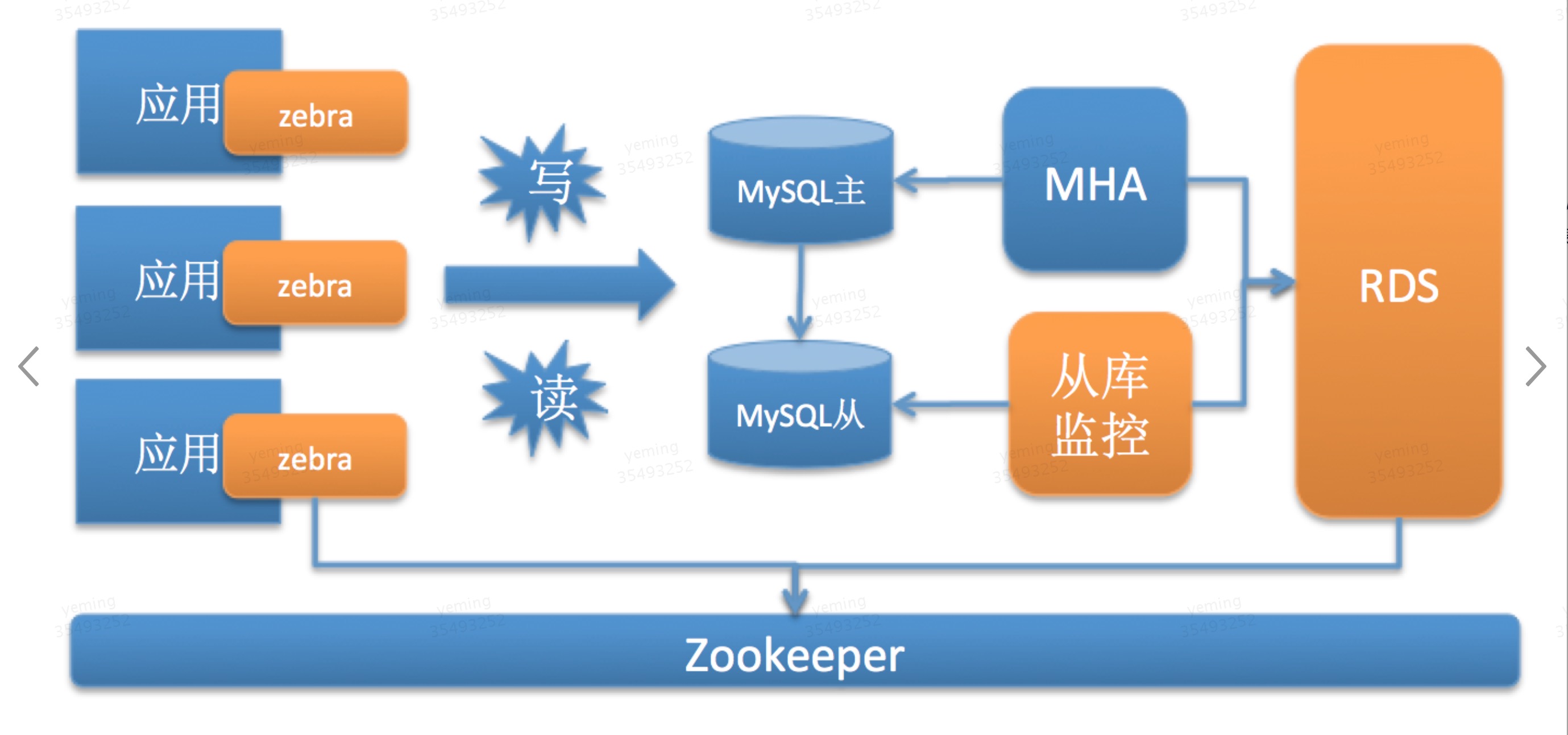
- zookeeper中存储着每一个数据库的路由信息、用户名密码等信息
- zebra客户端启动时会从zookeeper拉取数据库的信息,然后直连数据库。进行读写分离和分库分表。
- MHA组件是一个开源组件,主要负责数据库集群的主库的高可用。一旦发生主库故障,MHA会保证切换到某个从库上并把数据库保证一致性。
- 从库监控服务是一个自研的服务,主要负责数据库集群的从库的高可用。一旦发生从库故障,该服务会把该从库自动摘除。
- RDS是一个DBA一站式管理平台,负责数据库的创建、维护、扩容,以及最重要的zebra的配置信息的维护。
zebra客户端
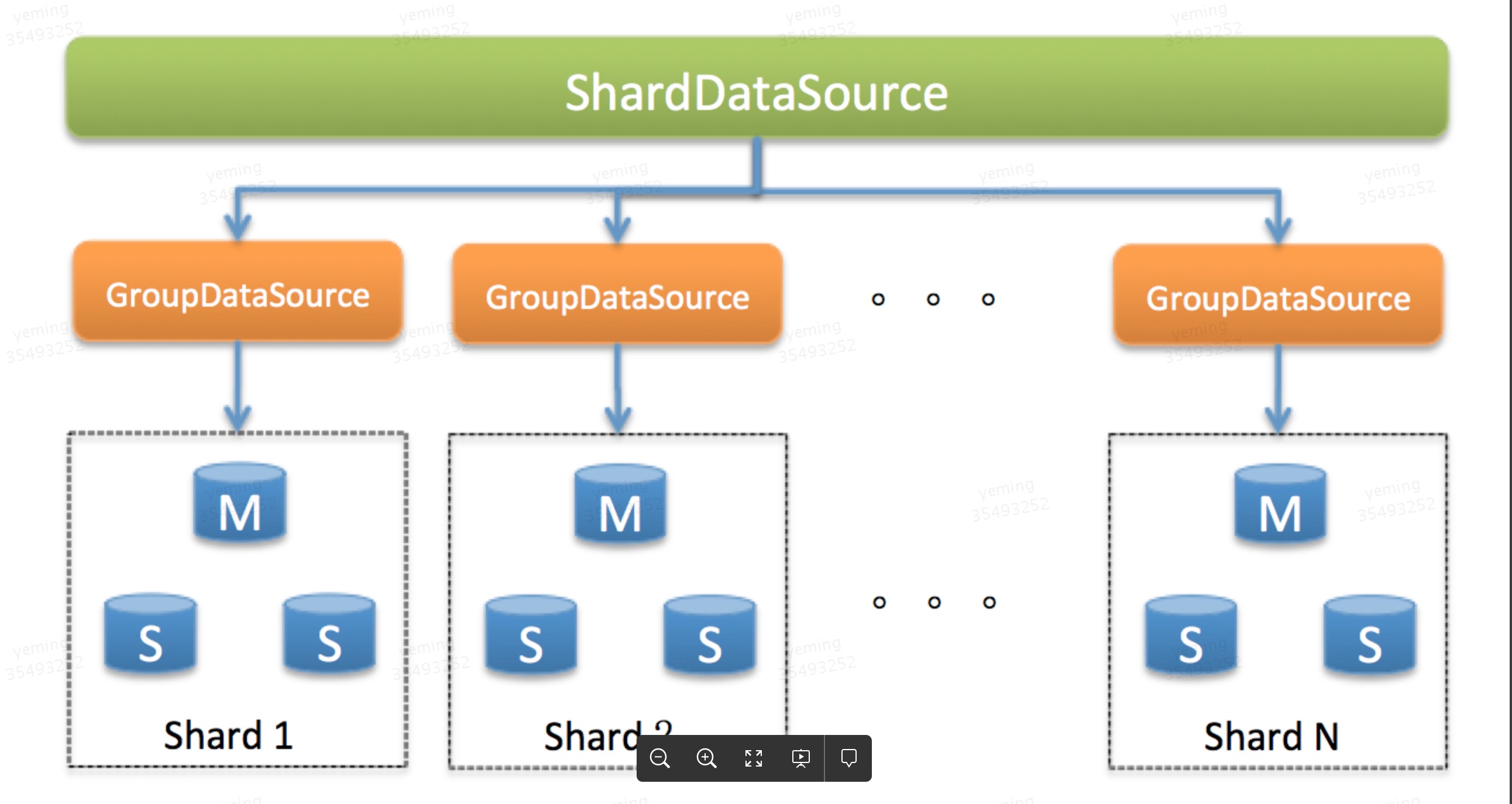
zebra中主要包括三个实现了JDBC协议的数据源,分别是:
- ShardDataSource:负责分库分表的连接池,它主要判断SQL的落到哪个分片上,然后把相应的SQL经过处理后发送给GroupDataSource。它负责连接多个数据库集群,因此它会包含若干个GroupDataSource。
- GroupDataSource:负责读写分离的连接池,它主要负责判断SQL的读写操作,然后把相应的SQL发送给SingleDataSource。它负责连接一个数据库集群,因此它会包含若干个SingleDataSource。
- SingleDataSource:负责抽象底层使用的连接池类型(c3p0,druid,tomcat-jdbc等),然后直连每一个数据库实例。在上图中,每一个Master或者Slave,都对应一个SingleDataSource。
客户端源码分析
客户端源码主要包括两个部分启动阶段的初始化和sql请求的处理
- 初始化:主要是应用启动阶段,对上述3个dataSource实例化,初始化相关配置,主要包括初始化上述3个dataSource的关系,建立与物理数据库之间的连接,添加一些配置变更的listener(通过zk监听配置,failover时候重建本地数据源,限流,流量路由)
- sql处理:主要包括sql解析,路由,改写,执行,结果合并几个步骤
初始化
SingleDataSource初始化
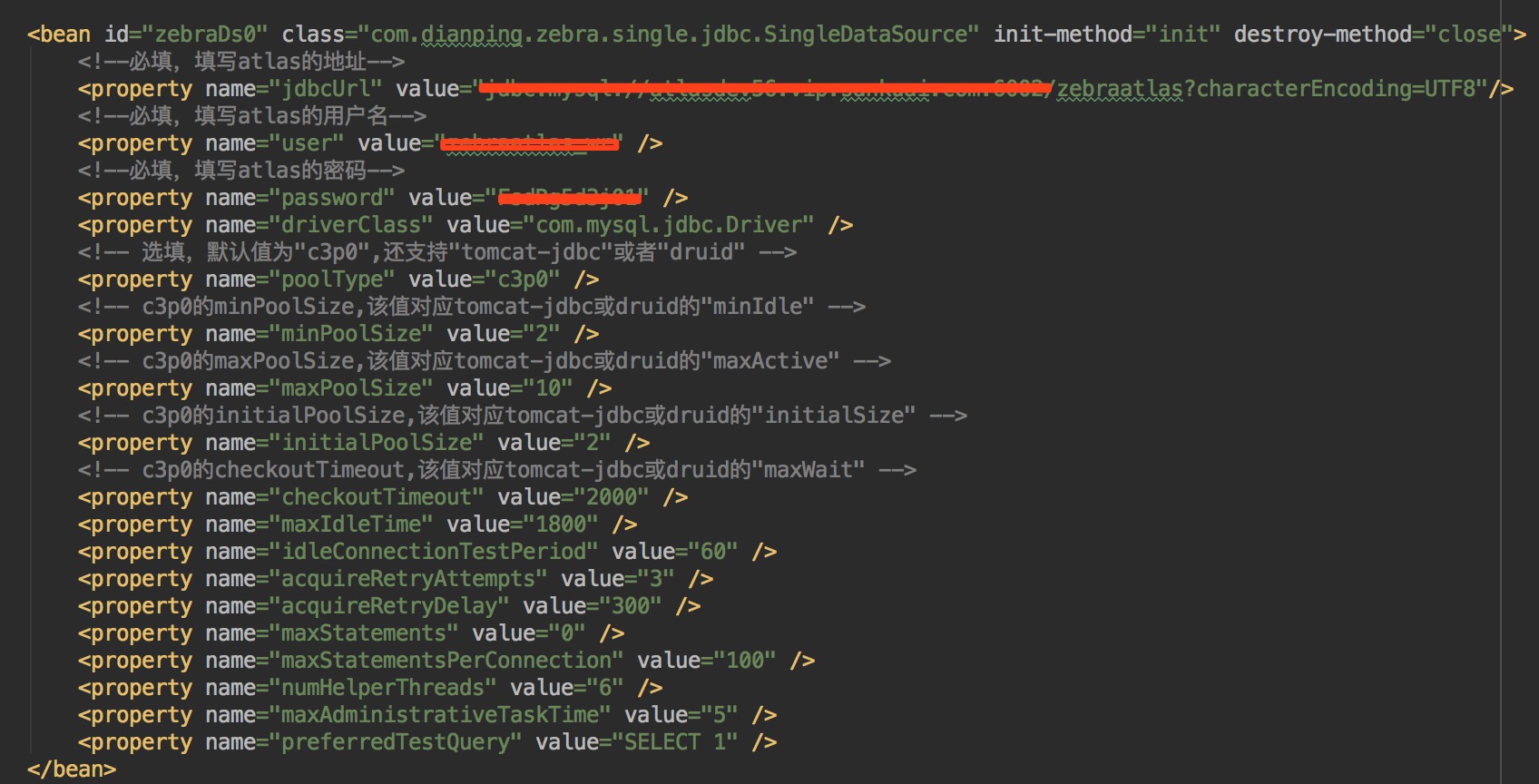 上图是一个SingDataSource的xml配置,最开始的jdbcUrl,password,user,driver这个是连接mysql服务端需要的,后面的一些参数就是配置数据库连接池(c3p0,tomcat-jdbc,dbcp,druid)的一些通用的参数配置
上图是一个SingDataSource的xml配置,最开始的jdbcUrl,password,user,driver这个是连接mysql服务端需要的,后面的一些参数就是配置数据库连接池(c3p0,tomcat-jdbc,dbcp,druid)的一些通用的参数配置
public synchronized void init() {
if (!init) {
mergeDataSourceConfig();
this.withDefalutValue = false;
if (this.getClass().isAssignableFrom(SingleDataSource.class)) {
if (!this.poolType.equals(Constants.CONNECTION_POOL_TYPE_C3P0)) {
this.withDefalutValue = true;
}
}
this.dataSourcePool = DataSourcePoolFactory.buildDataSourcePool(this.config);
this.filters = FilterManagerFactory.getFilterManager().loadFilters("cat,mtrace,tablerewrite,sqlrewrite",
configManagerType);
initDataSourceWithFilters(this.config);
init = true;
}
}
private DataSource initDataSourceWithFilters(final DataSourceConfig value) {
if (filters != null && filters.size() > 0) {
JdbcFilter chain = new DefaultJdbcFilterChain(filters) {
@Override
public DataSource initSingleDataSource(SingleDataSource source, JdbcFilter chain) {
if (index < filters.size()) {
return filters.get(index++).initSingleDataSource(source, chain);
} else {
return source.initDataSourceOrigin(value);
}
}
};
return chain.initSingleDataSource(this, chain);
} else {
return initDataSourceOrigin(value);
}
}
private DataSource initDataSourceOrigin(DataSourceConfig value) {
DataSource result = this.dataSourcePool.build(value, withDefalutValue);
if (!this.lazyInit) {
Connection conn = null;
try {
conn = result.getConnection();
logger.info(String.format("dataSource [%s] init pool finish", value.getId()));
} catch (SQLException e) {
logger.error(String.format("dataSource [%s] init pool fail", value.getId()), e);
} finally {
try {
if (conn != null) {
conn.close();
}
} catch (SQLException e) {
logger.error(String.format("dataSource [%s] init pool fail", value.getId()));
}
}
}
return result;
}上面的代码init方法中的this.dataSourcePool = DataSourcePoolFactory.buildDataSourcePool(this.config);这里是通过xml中的参数创建一个对应的数据库连接池(c3p0,tomcat-jdbc,dbcp,druid),然后最后一个initDataSourceOrigin方法,判断是否是lazyInit;如果不是,直接建立一个与mysql服务端的一个长连接。所以SingleDataSource初始化主要是创建一个真实的数据库连接池dataSourcePool,后续从SingleDataSource获取连接其实都是从dataSourcePool获取一个Connection
GroupDataSource初始化
负责读写分离的连接池,它主要负责判断SQL的读写操作,然后把相应的SQL发送给SingleDataSource。它负责连接一个数据库集群,因此它会包含若干个SingleDataSource
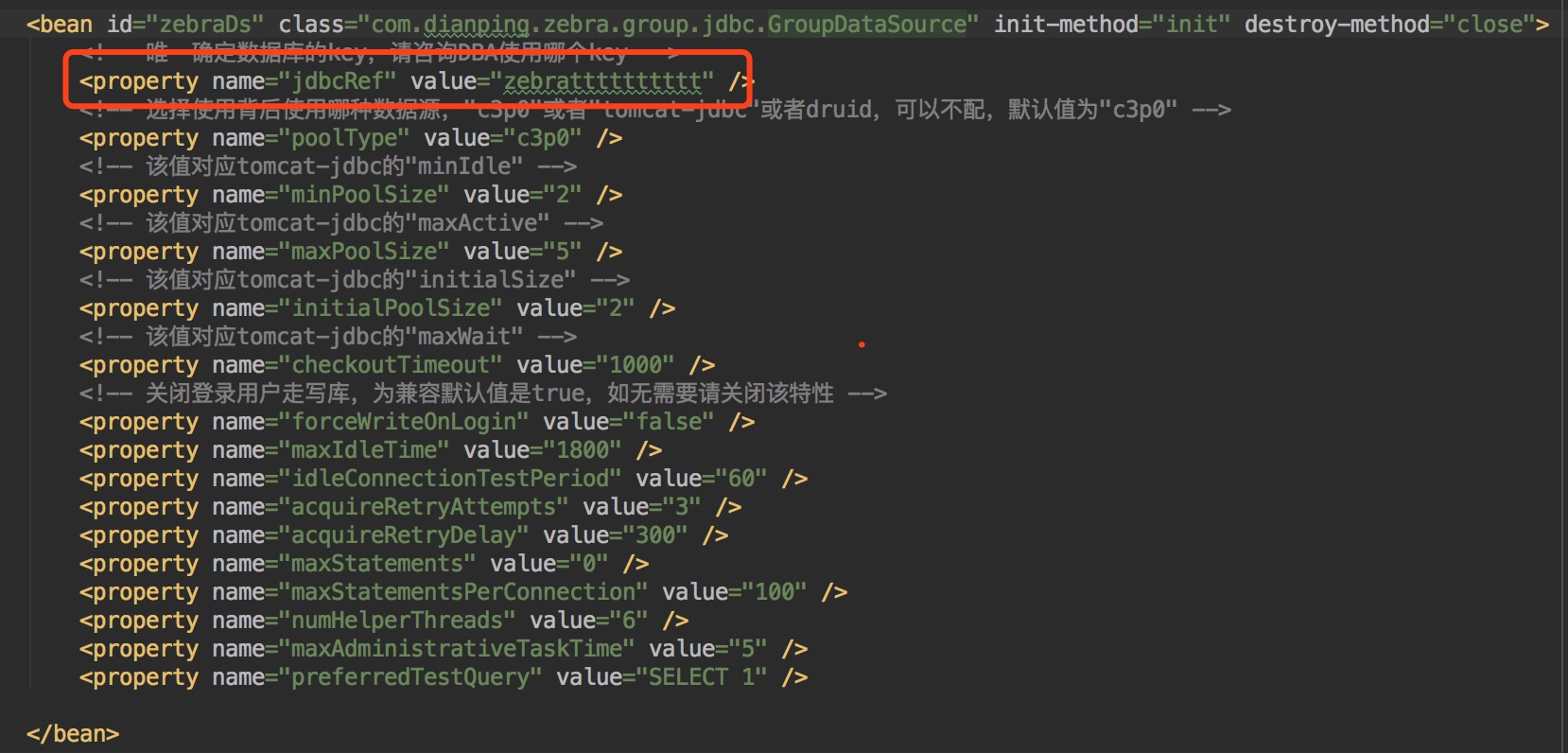 上图里面我们要说明下jdbcRef,如果要使用读写分离功能,需要在我们管理平台RDS上申请一组读写数据库,比如DB-1-WRITE,DB-1-REDAD,DB-2-READ,这里DB-1负责所有写请求,DB-1和DB-2共同负责读请求(流量可以配置)。以上2个数据库会关联一个jdbcRef保存在zk上面,所以上述xml里面直接配置了jdbcRef,启动时候从zk获取对应的主从结构。
上图里面我们要说明下jdbcRef,如果要使用读写分离功能,需要在我们管理平台RDS上申请一组读写数据库,比如DB-1-WRITE,DB-1-REDAD,DB-2-READ,这里DB-1负责所有写请求,DB-1和DB-2共同负责读请求(流量可以配置)。以上2个数据库会关联一个jdbcRef保存在zk上面,所以上述xml里面直接配置了jdbcRef,启动时候从zk获取对应的主从结构。
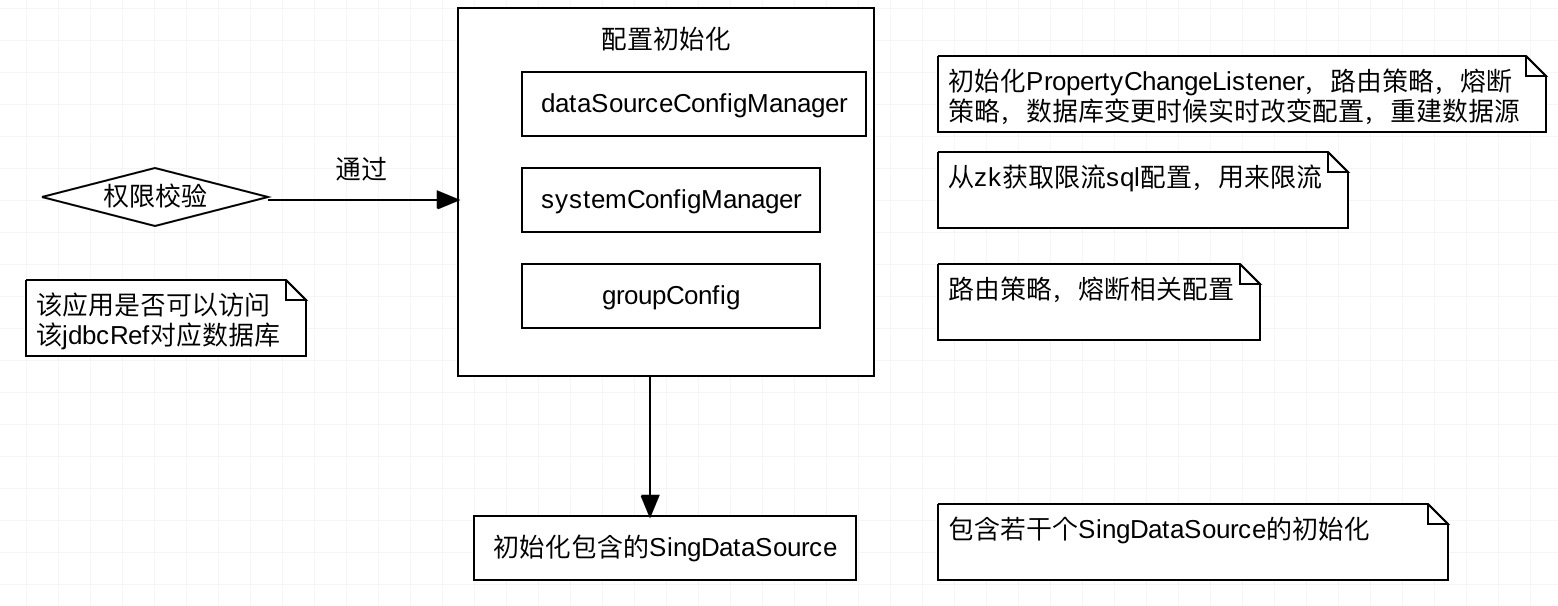 GroupDataSource初始化从先从zk获取group相关的配置,主要是读写分离,路由负载均衡策略,限流熔断策略,并注册对这些配置的实时监听,然后从zk获取jdbc对应的若干个SingleDataSource并分别初始化
GroupDataSource初始化从先从zk获取group相关的配置,主要是读写分离,路由负载均衡策略,限流熔断策略,并注册对这些配置的实时监听,然后从zk获取jdbc对应的若干个SingleDataSource并分别初始化
ShardDataSource初始化
负责分库分表的连接池,它主要判断SQL的落到哪个分片上,然后把相应的SQL经过处理后发送给GroupDataSource。它负责连接多个数据库集群,因此它会包含若干个GroupDataSource(或者直接多个SingDataSource)
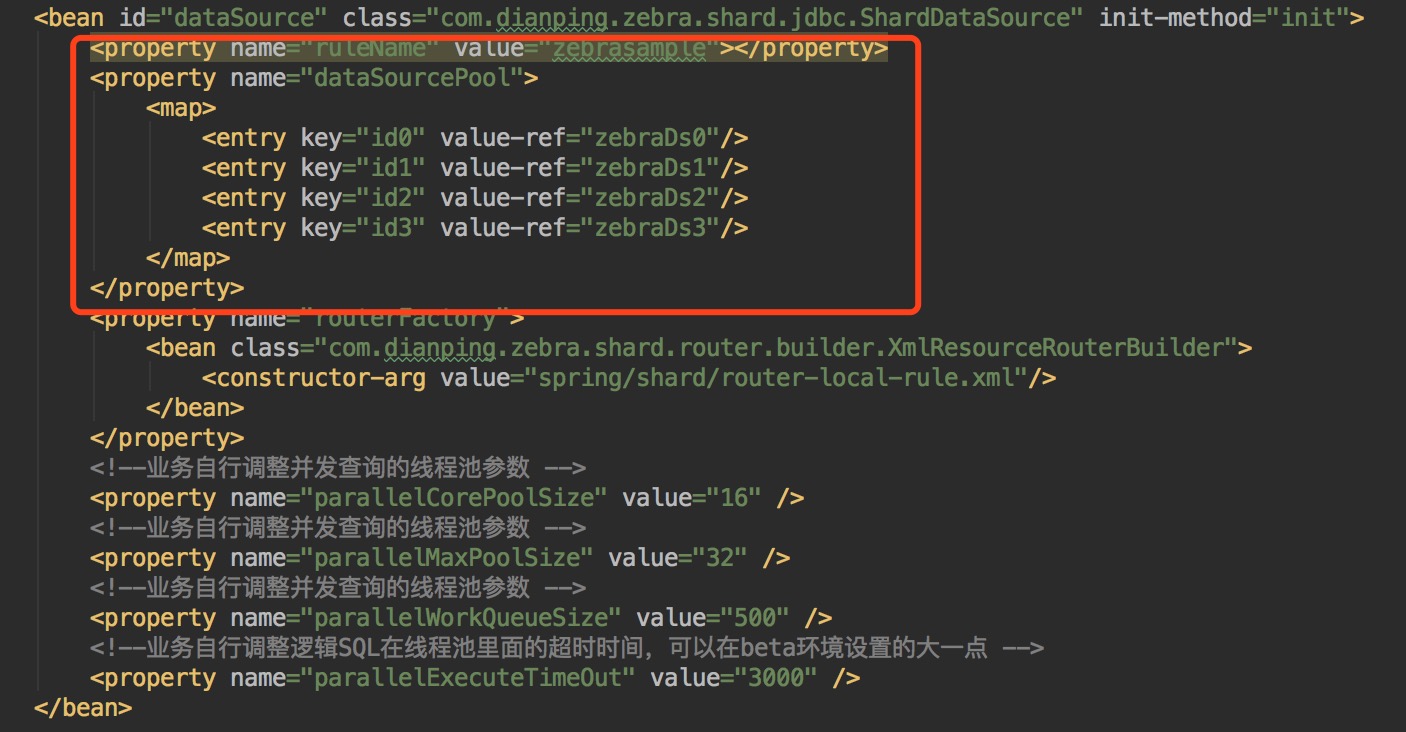 上面的配置稍微解释下
上面的配置稍微解释下
- ruleName:分表分表规则,集中式配置在zk上面
- dataSourcePool:配置若干个GroupDataSource或者SingleDataSource
- routerFactory:本地分表规则,先获取本地分库分表规则,如果没有配置,则从zk上获取ruleName分库分表规则
router-local-rule.xml
<router-rule>
<table-shard-rule table="Feed" generatedPK="id">
<shard-dimension dbRule="(#id#.intValue() % 8).intdiv(2)"
dbIndexes="id[0-3]"
tbRule="#id#.intValue() % 2"
tbSuffix="alldb:[0,7]"
isMaster="true">
</shard-dimension>
</table-shard-rule>
</router-rule>public void init() {
if (StringUtils.isNotBlank(ruleName)) {
if (configService == null) {
configService = ConfigServiceFactory.getConfigService(configManagerType, ruleName);
}
if (routerFactory == null) {
routerFactory = new LionRouterBuilder(ruleName, defaultDatasource);
}
} else {
if (dataSourcePool == null || dataSourcePool.isEmpty()) {
throw new IllegalArgumentException("dataSourcePool is required.");
}
if (routerFactory == null) {
throw new IllegalArgumentException("routerRuleFile must be set.");
}
}
this.initFilters();
initInternal();
}
private void initInternal() {
this.router = routerFactory.build();
if (dataSourceRepository == null) {
dataSourceRepository = DataSourceRepository.getInstance();
}
if (dataSourcePool != null) {
dataSourceRepository.init(dataSourcePool);
} else {
this.shardDataSourceCustomConfig.setDsConfigProperties(this.dsConfigProperties);
dataSourceRepository.init(this.router.getRouterRule(), this.shardDataSourceCustomConfig);
}
// init thread pool
SQLThreadPoolExecutor.getInstance();
// init SQL Parser
SQLParser.init();
if (ruleName != null) {
logger.info(String.format("ShardDataSource(%s) successfully initialized.", ruleName));
} else {
logger.info("ShardDataSource successfully initialized.");
}
}dataSourcePool包含若干个GroupDataSource或者SingleDataSource,先依赖这些DataSource的初始化。
routerFactory是本息xml配置的分库分表规则,如果没有配置,则从zk上获取分库分表配置,规则引擎是基于groovy的脚本,可以动态变更。
sql处理
sql处理主要包括,从连接池获取连接,创建preparedStatement,然后sql解析,路由,改写,执行,结果合并(路由,改写,结果合并是读写分离和分库分表才有的)
mybatis,jdbc知识储备
@Test
public void test() throws IOException {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
conn = ds.getConnection();
stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT * From Cluster");
while (rs.next()) {
System.out.println(rs.getString(2));
}
}以上是jdbc处理一条sql的,主要包括获取连接,创建preparedStatement,执行
SimpleExecutor
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection);
handler.parameterize(stmt);
return stmt;
}上述是mybatis中的SimpleExecutor类封装好了jdbc的操作。上述的Connection connection = getConnection(statementLog);最终会调用上述初始化的DataSource的getConnection方法。
sql解析,路由,改写,执行,结果合并
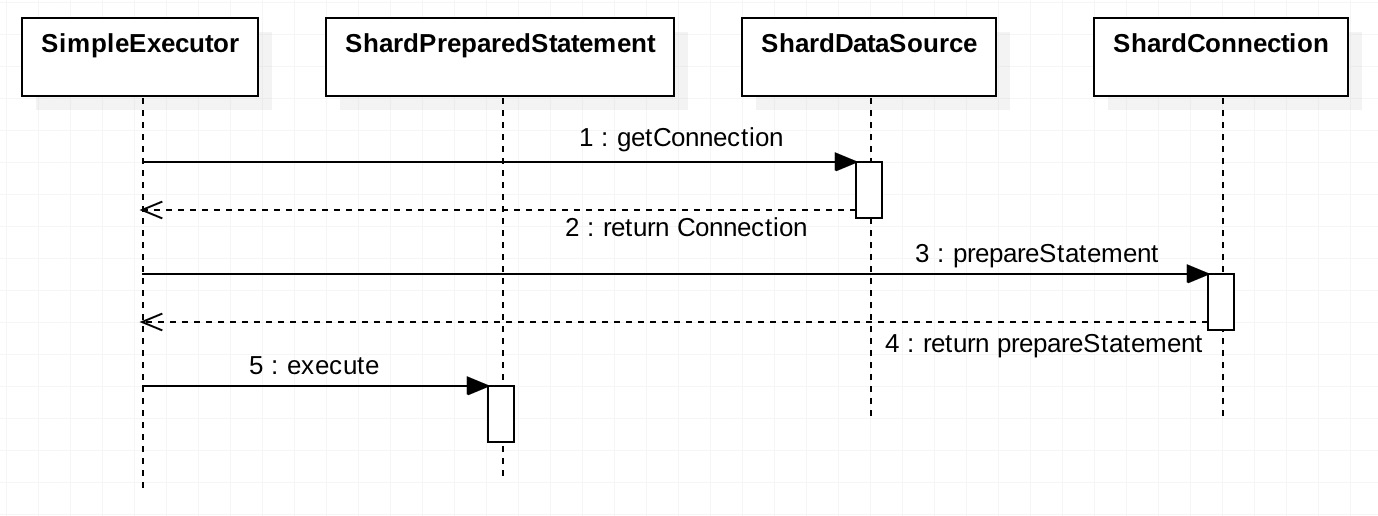 最终调用ShardPreparedStatement的execute方法
最终调用ShardPreparedStatement的execute方法
public boolean execute() throws SQLException {
SqlType sqlType = getSqlType(sql);
if (sqlType == SqlType.SELECT || sqlType == SqlType.SELECT_FOR_UPDATE) {
executeQuery();
return true;
} else if (sqlType == SqlType.INSERT || sqlType == SqlType.UPDATE || sqlType == SqlType.DELETE
|| sqlType == SqlType.REPLACE) { // add for replace
executeUpdate();
return false;
} else {
throw new SQLException("only select, insert, update, delete, replace sql is supported");
}
}这里可以看到对于查询和更新的流程是不一样的,查询流程要比更新流程复杂,因为查询操作不需要传分表字段值,而更新操作必须要传分表字段值,下面我们来看下查询操作。
private ResultSet executeQueryWithFilter() throws SQLException {
ResultSet specRS = beforeQuery(sql);
if (specRS != null) {
this.results = specRS;
this.updateCount = -1;
attachedResultSets.add(specRS);
return this.results;
}
RouterResult routerTarget = routingAndCheck(sql, getParams());
rewriteAndMergeParms(routerTarget.getParams());
ShardResultSet rs = new ShardResultSet();
rs.setStatement(this);
rs.setRouterTarget(routerTarget);
attachedResultSets.add(rs);
this.results = rs;
this.updateCount = -1;
MergeContext context = routerTarget.getMergeContext();
// 有orderby和limit的单个查询用切分成多个的方式进行数据获取
if (context.isOrderBySplitSql()) {
executeOrderyByLimitQuery(rs, sql, routerTarget);
} else {
normalSelectExecute(rs, sql, routerTarget);
}
return this.results;
}- sql解析:用的是druid的sql解析
- sql改写:RouterResult routerTarget = routingAndCheck(sql, getParams())这里对客户端的sql(一般是mybatis mapper中的sql)改写,将表名改写为物理上真实的表名,并关联对应表名的数据库
- sql执行:如果改写后的sql对应多条物理db的sql,那么后台创建多个任务提交到线程池并行的去执行,若只有一条sql则直接执行
- 结果合并:将上述sql执行的结果根据指定条件合并返回
zebra高可用
基本架构
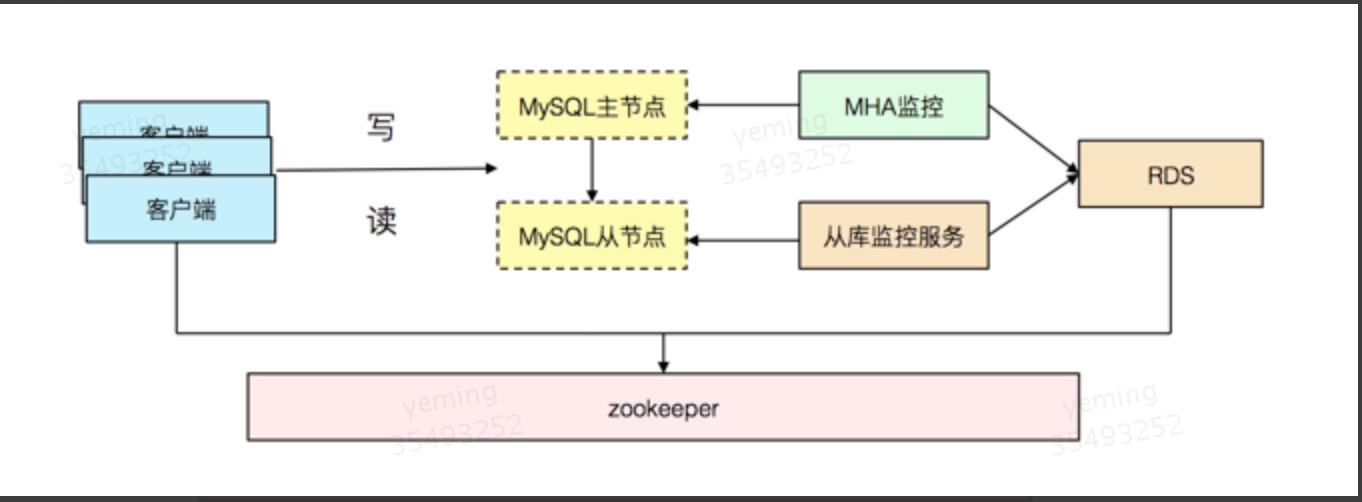 其中MHA负责主库切换,从库监控服务负责从库切换。
主库和从库均使用实体IP。
其中MHA负责主库切换,从库监控服务负责从库切换。
主库和从库均使用实体IP。
主库的高可用
利用MHA进行master节点的可用性监控,在发生故障,master节点不可用时,MHA进行mysql层的主从切换,切换成功后通知zebra新master节点的IP,由zebra负责应用访问层的切换。切换流程如下:
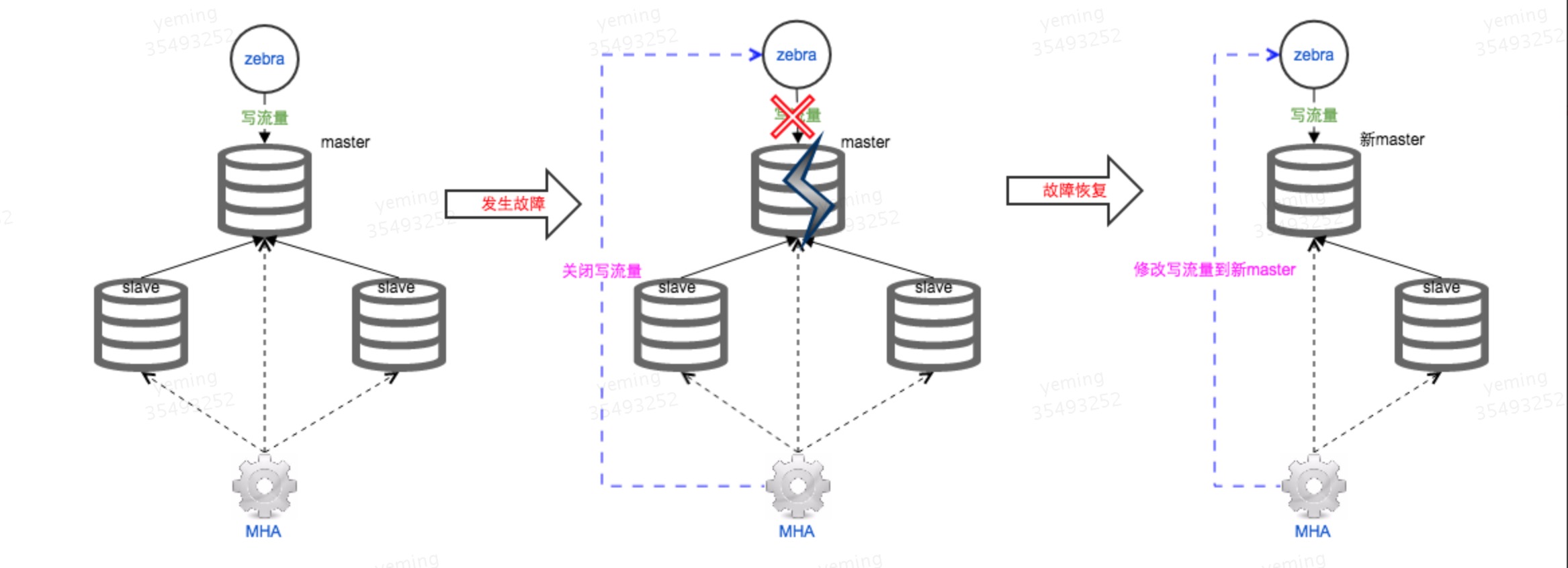 - MHA对MySQL集群进行监控管理
- 当主库发生故障时,MHA通知zebra对主库的写进行关闭,并进行MySQL集群的主从切换(切换期间应用无法写数据)
- zebra禁止掉对故障集群的写操作
- MHA切换成功,通知zebra新的写数据IP
- zebra用新的写IP替换老IP,开放应用访问。
- MHA对MySQL集群进行监控管理
- 当主库发生故障时,MHA通知zebra对主库的写进行关闭,并进行MySQL集群的主从切换(切换期间应用无法写数据)
- zebra禁止掉对故障集群的写操作
- MHA切换成功,通知zebra新的写数据IP
- zebra用新的写IP替换老IP,开放应用访问。
从库的高可用
由zebra-monitor的监控服务负责,时时监控线上MySQL从库的健康状况,如果出现从库“故障”,将会通知zebra将读流量转移到其他可读节点,实现从库的“故障”转移。
分配粒度
根据集群进行分配 同一个集群上的所有实例在一台机器上监控
负载方式
根据机房位置进行分配: 北京侧集群由北京侧机器监控,上海侧集群由上海侧机器监控。
(同侧集群id%监控机器数)结果为当前机器所需监控的集群,保存在数据库中,如果有新机器上线则对数据库中的数据进行刷新并通知所有活跃机器重新加载监控集群。加载集群的同时加载对应集群上的所有实例,实例信息由单独线程动态更新,刷新频率为10min。
监控逻辑
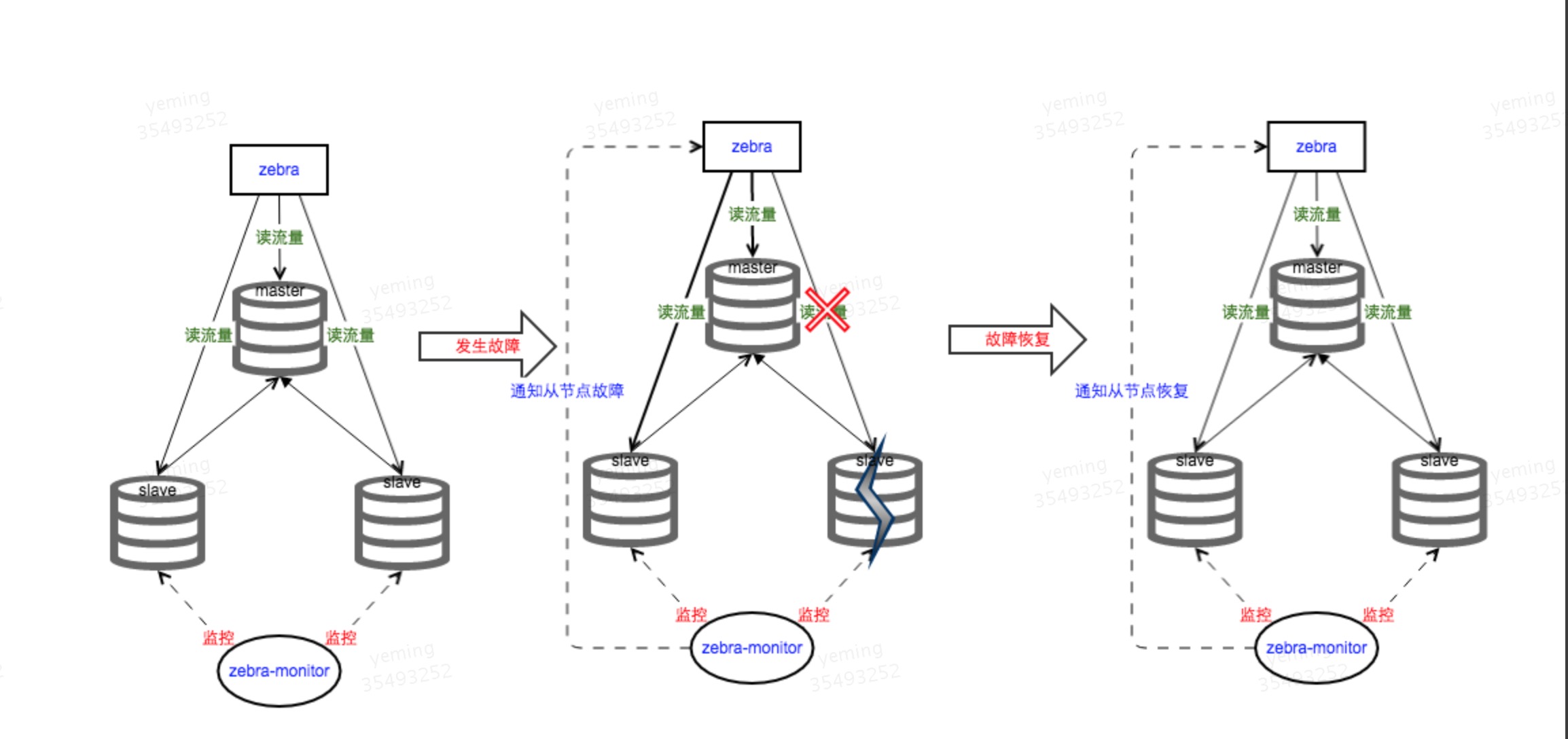 监控首先使用'select 1' 测试是否可以连通数据库, 连接没有问题则使用 'show slave status' 获取到'second_behind_master'字段来得到该从库上的延迟,从而做出判断。
监控首先使用'select 1' 测试是否可以连通数据库, 连接没有问题则使用 'show slave status' 获取到'second_behind_master'字段来得到该从库上的延迟,从而做出判断。
markdown的场景
(1)30s内从库连续ping不通。 (从库宕机)
(2)30s内 second_behind_master取到的延迟为null。 (主从同步中断)
(3)延迟超过阈值。(可根据每个库的敏感程度进行个性化配置,需要进行另外配置)
markup的场景
30s内能够连续ping通并且主从延迟为0.
使用情况
从库被markdown之后,zebra客户端会收到zk的通知进行动态刷新,重建本地数据源配置,新的流量会导入到正常的从库上。老的数据源会在全部sql执行完成后被close。
目前以实例为单位进行配置,即如果一个实例延迟到达阈值,则该实例上所有从库都会被markdown。
但是考虑到每个库对延迟的敏感程度不同,我们支持库级的配置,一个实例上的不同库可以有不同的延迟阈值。
